论文笔记:RAFT: Recurrent All-Pairs Field Transforms for Optical Flow
本文介绍了一种叫做 Recurrent All-Pairs Field Transforms (RAFT) 的光流网络,在数据集中取得了 SOTA 的结果。主要亮点如下:
(1)State-of-the-art accuracy:本文在 KITTI 相对现有最好结果取得了 16% 的误差下降,达到 5.10%(F1)。在 Sintel 上取得了 30% 的误差下降(像素误差)。是目前最好的结果。
(2)Strong generalization:仅在仿真数据集训练时,RAFT 相比同样在仿真数据集训练的最好的网络结果有 40% 的误差下降。
(3)High efficiency: RAFT 在 1088×436 videos 可以达到 10 FPS 的速度( 1080Ti GPU)。同时在训练迭代次数上,减少了10倍。
1 Approach
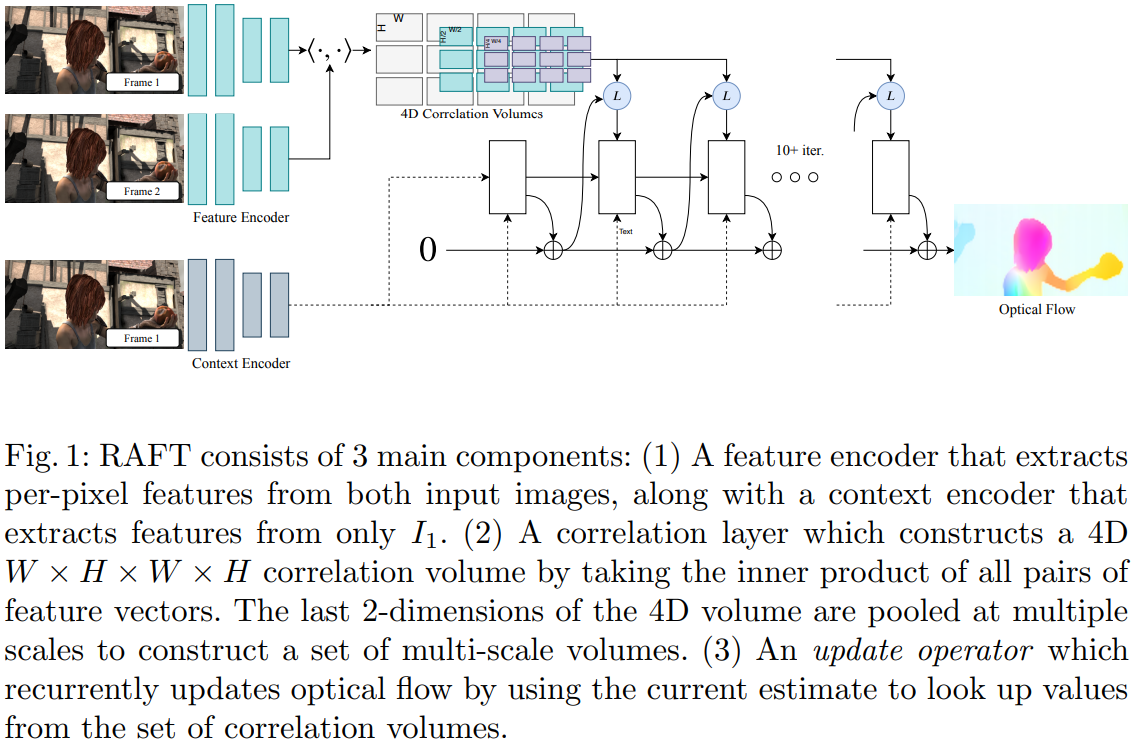
RAFT 网络包含三个部分:
(1)Feature Encoder:提取对应每个像素的特征
(2)Correlation Layer:对所有特征求内积矩阵,大小为 \(W \times H \times W \times H\)
(3)Update Operator:使用 GRU 循环神经网络更新光流,通过迭代获得更好结果
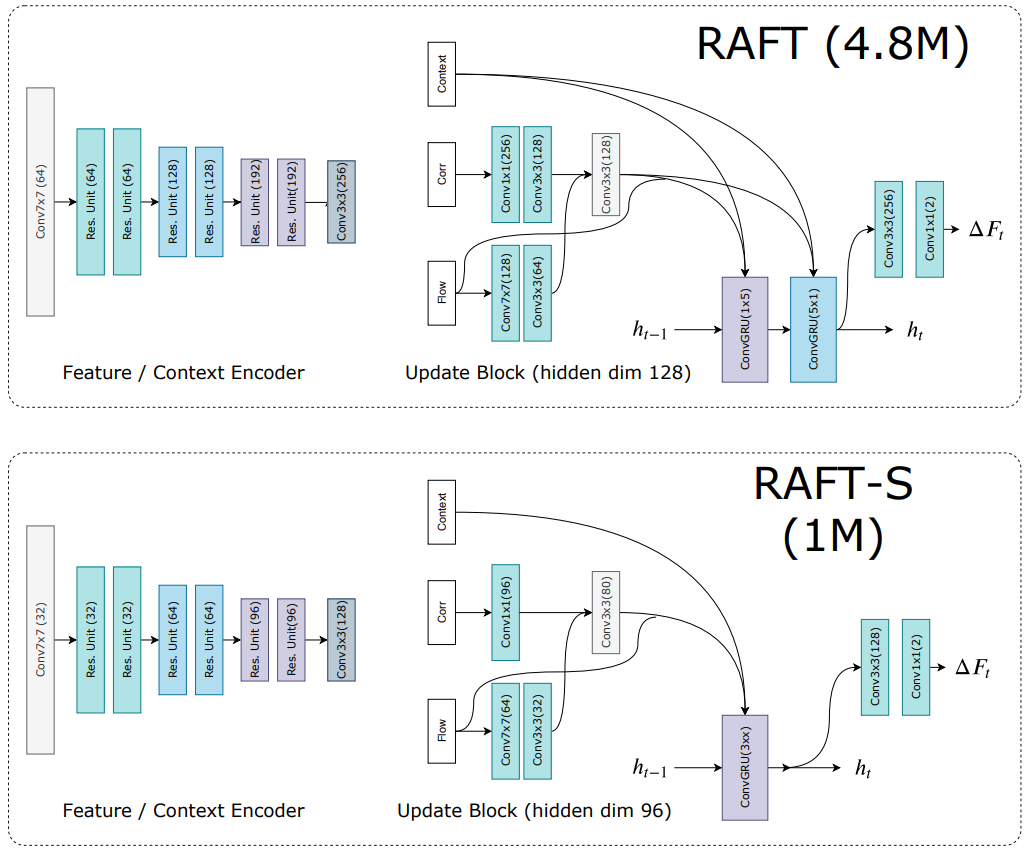
1.1 Feature Extraction
对于两幅图 \(I_1\) 和 \(I_2\) 都需要提取特征,该网络称之为 Feature Encoder。上图左半边展示了 Feature Extraction 网络部分,该部分最终输出一个 1/8 大小的特征图:\(g_{\theta}: \mathbb{R}^{H \times W \times 3} \mapsto \mathbb{R}^{H / 8 \times W / 8 \times D}\),其中 \(D=256\)。除了 Feature Encoder 外作者还引入一个 Context Encoder,输出为 \(h_{\theta}\),这一网络与 Feature Encoder 相同,但只对 \(I_1\) 进行。
1.2 Computing Visual Similarity
这一部分就是给定两幅图像特征 \(g_{\theta}\left(I_{1}\right) \in \mathbb{R}^{H \times W \times D}\) 和 \(g_{\theta}\left(I_{2}\right) \in \mathbb{R}^{H \times W \times D}\),求所有特征的点积:
\(\mathbf{C}\left(g_{\theta}\left(I_{1}\right), g_{\theta}\left(I_{2}\right)\right) \in \mathbb{R}^{H \times W \times H \times W}, \quad C_{i j k l}=\sum_{h} g_{\theta}\left(I_{1}\right)_{i j h} \cdot g_{\theta}\left(I_{2}\right)_{k l h}\tag{1}\)Correlation Pyramid
对应于提取的4层特征,本文创建了4层相关金字塔,分别为:\(\left\{\mathbf{C}^{1}, \mathbf{C}^{2}, \mathbf{C}^{3}, \mathbf{C}^{4}\right\}\),对于后两层则分别使用 pooling 进行下采样。流程如下图所示:

Correlation Lookup
给定一个光流场(flow field) \((\mathbf{f}_1, \mathbf{f}_2)\),对于 \(I_1\) 上的像素 \(x=(u, v)\),其在 \(I_2\) 上对应位置为 \(\mathbf{x}^{\prime}=\left(u+f^{1}(u), v+f^{2}(v)\right)\)。我们定义一个局部邻域:
\(\mathcal{N}\left(\mathbf{x}^{\prime}\right)_{r}=\left\{\mathbf{x}^{\prime}+\mathbf{d} \mathbf{x} \mid \mathbf{d} \mathbf{x} \in \mathbb{Z}^{2},\|\mathbf{d} \mathbf{x}\|_{1} \leq r\right\}\tag{2}\)当后序遍历金字塔的每一层时,对于第k层 \(\mathbf{C}_{k}\),使用 \(\mathcal{N}\left(\mathbf{x}^{\prime} / 2^{k}\right)_{r}\) 进行索引。这一方式使得更低层级的邻域实际对应更大的感受野。例如对于 \(k=4\) 层级,采用 \(r=4\) 对应于原始分辨率就是 256 个像素。最终将所有层的特征叠加到一层。
Efficient Computation for High Resolution Images
\(\mathbf{C}_{i j k l}^{m}=\frac{1}{2^{2 m}} \sum_{p}^{2^{m}} \sum_{q}^{2^{m}}\left\langle g_{i, j}^{(1)}, g_{2^{m} k+p, 2^{m} l+q}^{(2)}\right\rangle=\left\langle g_{i, j}^{(1)}, \frac{1}{2^{2 m}}\left(\sum_{p}^{2^{m}} \sum_{q}^{2^{m}} g_{2^{m} k+p, 2^{m} l+q}^{(2)}\right)\right\rangle\tag{3}\)1.3 Iterative Updates
迭代更新层是从一个初始的光流输出 \(\mathbf{f}_0=0\) 优化一系列光流序列的估计 \(\left\{\mathbf{f}_{1}, \ldots, \mathbf{f}_{N}\right\}\)(迭代 k 次)。更新层输入为 flow、correlation、context 上一次的隐藏层,输出为本次迭代的梯度 \(\Delta \mathbf{f}\),则本次迭代后的光流更新为:
\(\mathbf{f}_{k+1} = \Delta \mathbf{f} + \mathbf{f}_{k+1}\tag{4}\)最终通过训练这一时序网络将光流收敛到 \(\mathbf{f}_k → \mathbf{f}_∗\)。
Initialization
默认状态,我们将这一部分光流场设为 0,在视频模式时,我们可以利用之前的结果做 warm start。
Inputs
如图 2 所示,输入当前光流 \(\mathbf{f}_k\),经过两层卷积与经过一层卷积的 Correlation 叠加,最后再与 Context 直接叠加组成 GRU 输入的特征。
Update
更新层使用的主要是一个 GRU 单元,其中的全连接用卷积代替。该 GRU 定义为 ConvGRU,它的公式表述如下:
\(\begin{array}{l}z_{t}=\sigma\left(\operatorname{Conv}_{3 \times 3}\left(\left[h_{t-1}, x_{t}\right], W_{z}\right)\right) \\r_{t}=\sigma\left(\operatorname{Conv}_{3 \times 3}\left(\left[h_{t-1}, x_{t}\right], W_{r}\right)\right) \\ \tilde{h}_{t}=\tanh \left(\operatorname{Conv}_{3 \times 3}\left(\left[r_{t} \odot h_{t-1}, x_{t}\right], W_{h}\right)\right) \\ h_{t}=\left(1-z_{t}\right) \odot h_{t-1}+z_{t} \odot \tilde{h}_{t}\end{array}\tag{5}\)其中 \(x_t\) 就代表了刚才定义的 Input。
Flow Prediction
GRU 的输出经过两个卷积操作就变成了最终的光流,输出光流是 1/8 尺度的,在实际预测中会经过下述 Upsampling 操作转换成原始大小。
Upsampling
由于输出的光流是 1/8 尺度下的,因此为了得到原始分辨率尺度,Upsampling 部分在粗分辨率上通过周围共计 3x3 的网格预测进行差值,在这一部分使用了两个卷积操作并经过一个 softmax 得到一个 \(H/8×W/8×(8×8×9)\) 尺度的 mask。最终原始分辨率的光流就通过这一 mask 进行加权获得。网络输出就是得到一个 \(H \times W \times 2\) 的结果,其中2代表x、y坐标偏移。该层通过一个 PyTorch 中的 unfold 操作即可实现。
1.4 Supervision
我们的 Loss 定义如下:
\(\mathcal{L}=\sum_{i=1}^{N} \gamma^{N-i}\left\|\mathbf{f}_{g t}-\mathbf{f}_{i}\right\|_{1}\tag{6}\)在整个序列输出的光流预测与 \(f_{gt}\) 计算 \(l_1\) 距离,其中各阶段赋予不同的权重。在本文中 \(\gamma = 0.8\)。
2 Experiments
作者在 Sintel 和 KITTI 数据集进行了实验,结果如下:
Sintel

KITTI

数据如下
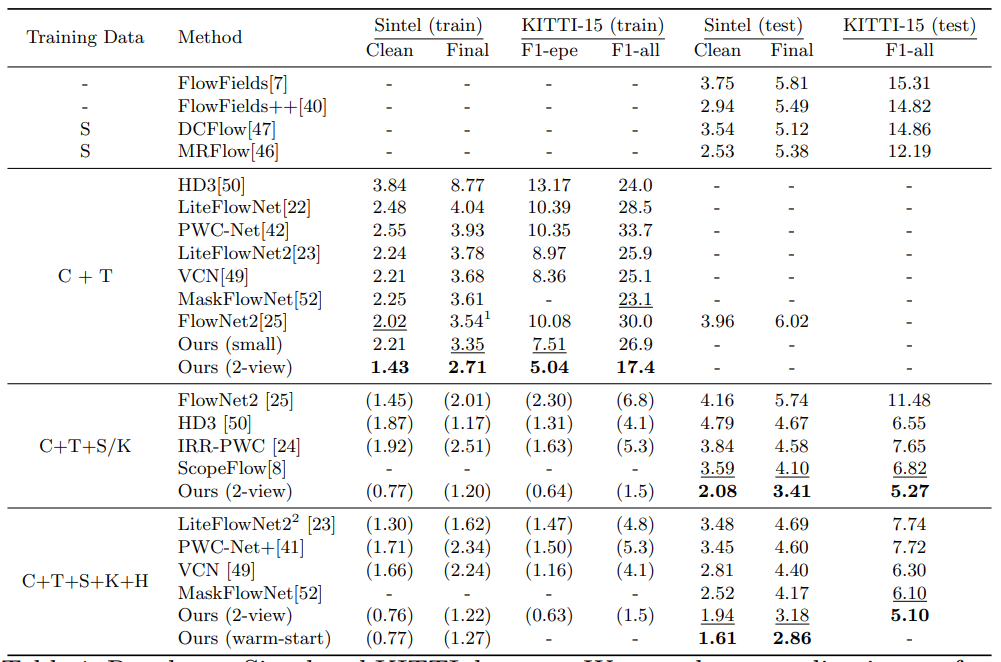
可以看出相比最新的几个网络,还是有很明显的提升的。具体内容可以参见原文。
个人小结
本篇是 ECCV 2020 Oral,在光流领域横扫了现有排行榜,可以说是订立了新的标准,值得学习。个人感觉其中的 GRU Update 模块起的作用很大,也起到了很好的提升迁移能力的作用,实际测试效果不错。但是这个网络整体计算量不小,压缩难度比较大。
