CVPR 2021 Image Matching 挑戰賽雙冠算法回顧
借之前我們給公司提供的文章,總結一下前一段時間參賽的一些實驗和思考。本文版權所有:曠視科技。原文鏈接:https://www.zhihu.com/question/32066833/answer/2041516754
Image Matching(圖像匹配)是計算機視覺領域最基礎的技術之一,它是指通過稀疏或者稠密特徵匹配的方式,將兩幅圖像相同位置的局部信息進行關聯。Image Matching 在很多領域均有廣泛應用,比如機器人、無人車、AR/VR、圖像/商品檢索、指紋識別等等。
在今年剛剛結束的 CVPR 2021 Image Matching 比賽中,曠視 3D 組獲得兩冠一亞的成績,本文介紹了他們的比賽方案、實驗和一些思考。



比賽介紹
圖像匹配是指將兩幅圖像具有相同或者相似屬性的內容或結構進行像素上的識別與對齊。一般而言,待匹配的圖像通常取自相同或相似的場景或目標,或者具有相同形狀或語義信息的其他類型的圖像對,從而具有一定的可匹配性。
Image Matching Challenge

本次 Image Matching Challenge(IMC) 比賽還是分為兩個賽道 unlimited keypoints 和 restricted keypoints,即每張圖片可提取特徵點數量分別小於 8k 和 2k。
今年 IMC 比賽一共有三個數據集,分別是 Phototourism、PragueParks 和 GoogleUrban,這三個數據集差異比較大,對算法的泛化能力要求比較高。主辦方希望找到一種方法在三個數據集上面表現都比較好的方法,所以最終排名是這三個數據集排名的平均。
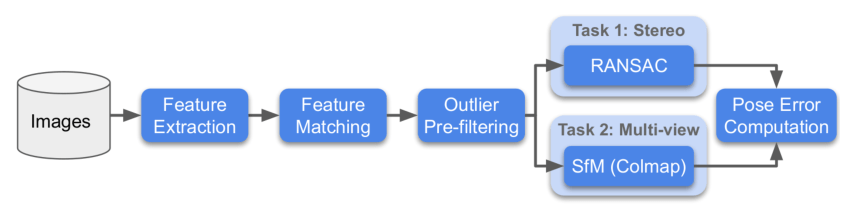
針對每個數據集,主辦方會採用兩種方法進行評估,分別是 Stereo 和 Multiview,然後分別求這兩個任務 rank。
- Stereo:通過兩張圖片進行匹配,然後解算F矩陣,求解實際的位姿誤差。
- Multiview:選取少部分圖片組成一個bags,通過bags進行建圖,通過3d模型求解不同圖片之間的位姿誤差。
下面為比賽流程圖:
SimLoc Match

SimLoc 也是包含不同場景的數據集,與 IMC 數據集不同之處是一個合成數據集,可以獲得完全準確的ground truth。
比賽有三個指標,最終使用匹配成功率當做最終的排名評測指標,三個指標分別是:
- 內點數量(越高越好)
- 匹配成功率,即匹配內點數量/所有提供的匹配對(越高越好)
- 負匹配對數量,當兩張圖片沒有共視區域時,匹配對應該越少越好
方案
數據分析


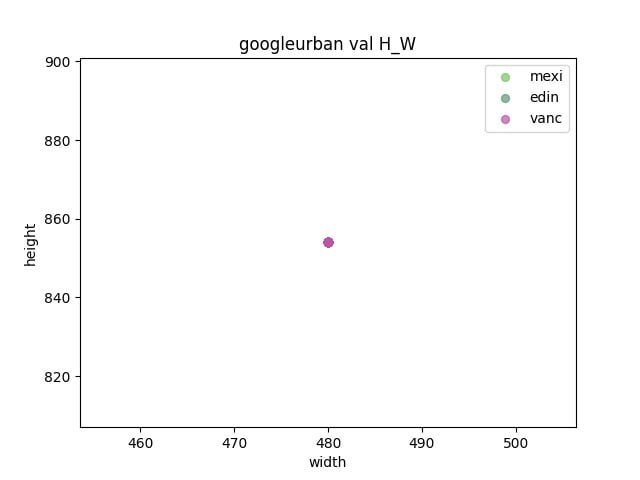
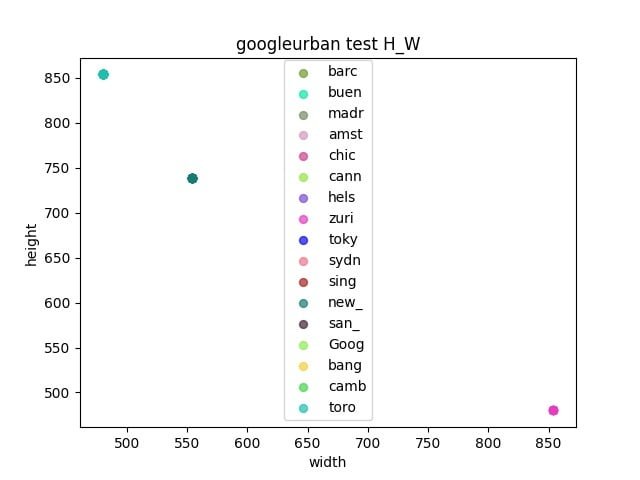
首先對比賽的三個數據集進行分析
- 觀察驗證集和測試集之間是否存在gap
- 通過統計各個數據集之間的長寬,來確定resize的大小
Pipeline
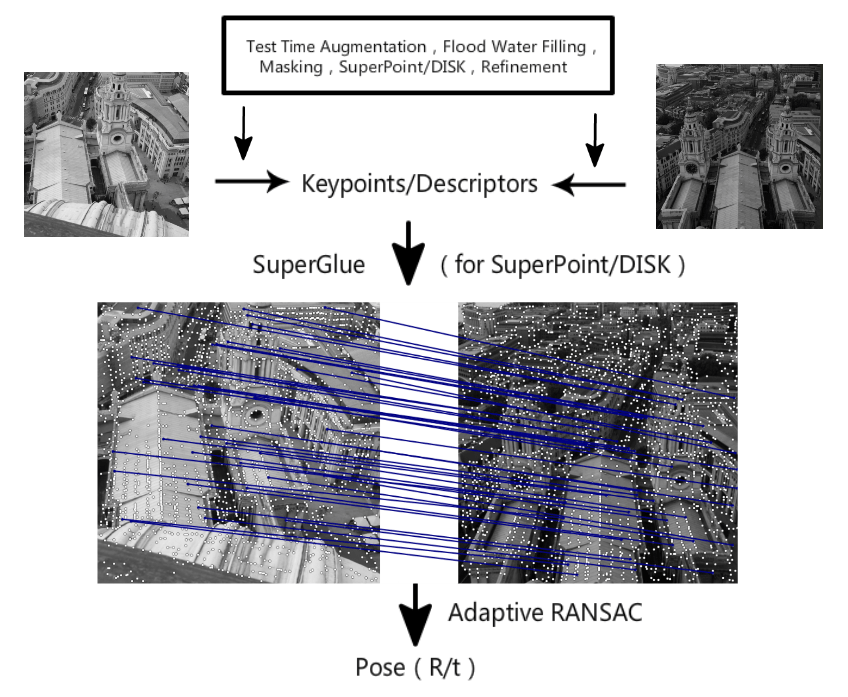
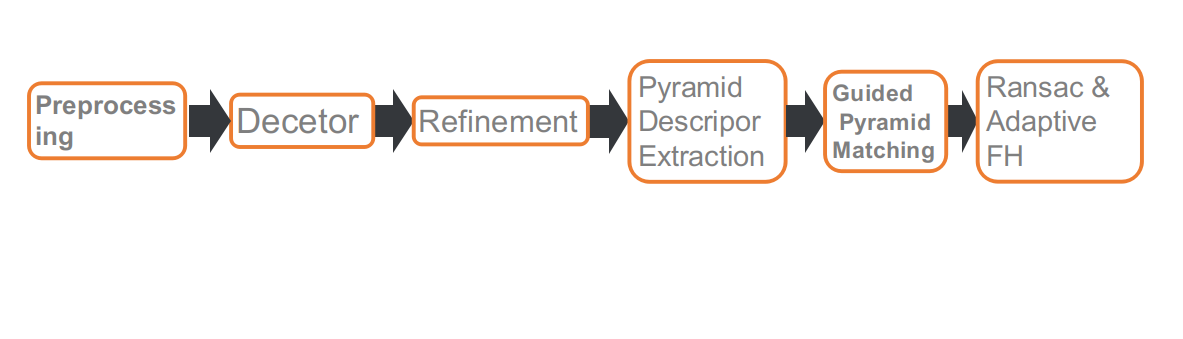
這是我們比賽的pipeline,一共包含六個部分。分別是:預處理,特徵點檢測,refine特徵點位置,多尺度或者多角度提取描述子,Guided 匹配和基於自適應FH的RANSAC。
預處理


IMC 賽道對特徵點數量有限制,所以特徵點的位置就比較重要,一些動態的物體比如行人,車輛,天空等等。對匹配求解位姿沒有作用,或者有負面作用。所以我們採用分割網絡將這些物體給 mask 掉,當提取特徵點的時候,會略過 mask 區域。
使用分割網絡進行預處理之後,我們發現了兩個問題。
- 一個是由於分割網絡的精確度不高,並不能很好的區分建築物和天空連接區域,會存在一些把建築物邊緣破壞掉情況,這樣不利於匹配。所以我們 mask 動態物體之後,對 mask 區域做了一個腐蝕處理,這樣可以把建築物的邊緣細節給保留下來。
- 另外一個問題是分割網絡算法針對真人和雕塑的泛化能力不是很好,當 mask 行人的時候,也會把雕塑給mask掉。而部分場景例如林肯數據集,雕塑上面的特徵點對匹配結果比較重要。針對這個情況,我們訓練了一個分類網絡來區分雕塑和行人,這樣既可以去掉行人又可以保留下來雕塑。
通過預處理操作,在 Phototourism 驗證集 Stereo 和 Multiview 任務分別提升1.1%和0.3%。
特徵點提取
Adapt Homographic
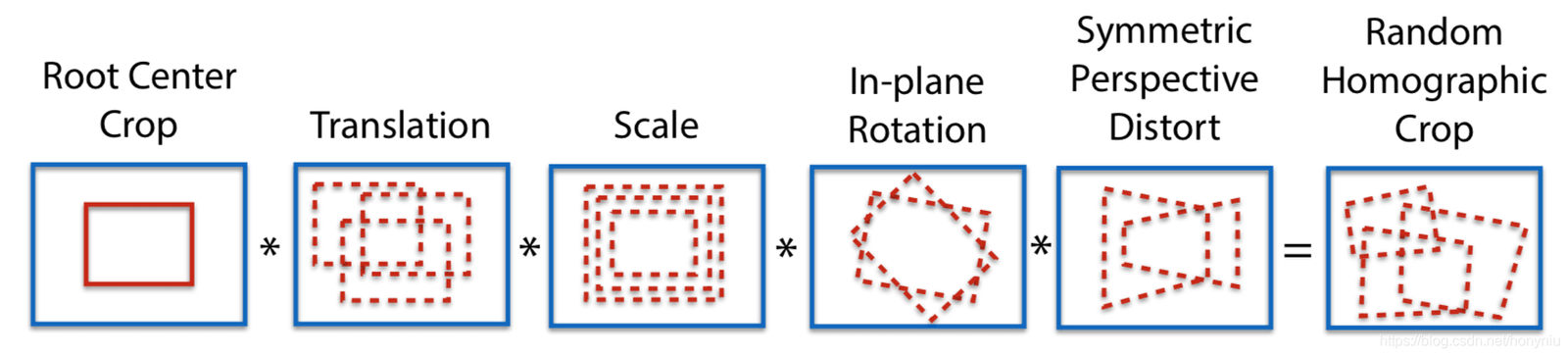
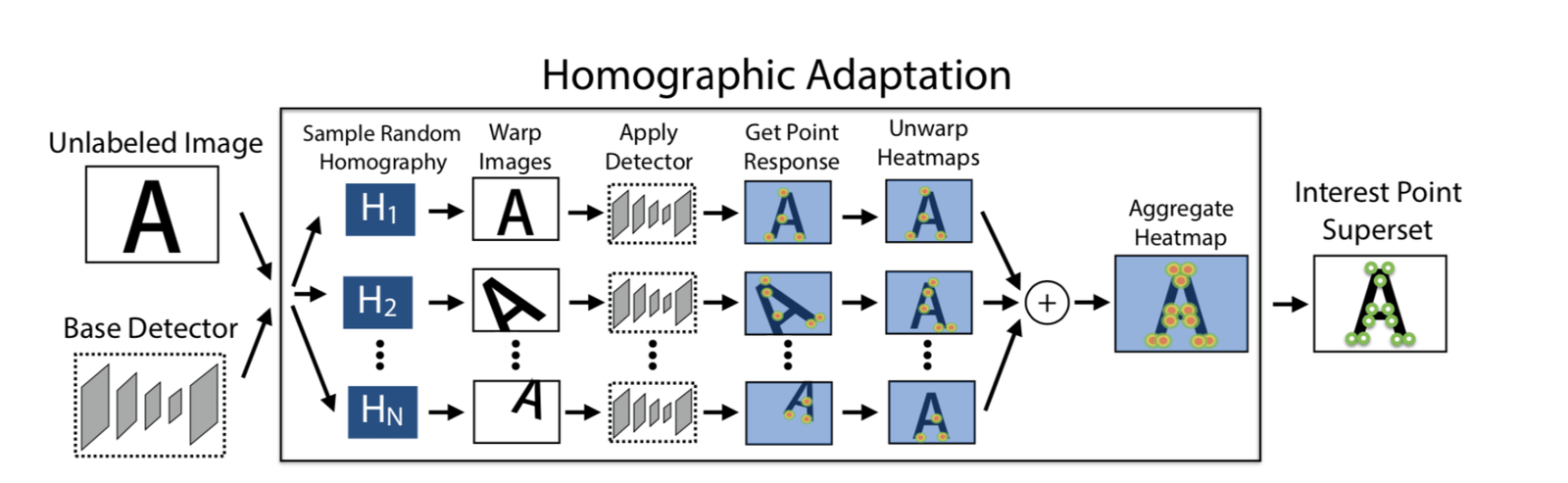
採用100次單應矩陣變換,得到100張變換後的圖像,在這些圖像上利用 SuperPoint 模型分別提取特徵點,可以得到n個特徵點的 heatmap,把這n個 heatmap 疊加到一些,得到最後的heatmap,然後再根據需要選擇特徵點。這樣做的好處一個是可以提取更多的特徵點,第二個是特徵點的位置也會更加合理一些。
通過使用 Adapt Homographic,在 Phototourism 驗證集 Stereo 和 Multiview 任務分別提升1.7%和1.3%。
Refinement
SuperPoint 提取出來的特徵點是整數,我們採用 soft argmax refinement 並且使用半徑為2的參數,進行亞像素化,使得特徵點位置更加準確。採用 refinement 方法,在 Phototourism 驗證集 Stereo 和 Multiview 任務分別提升0.8%和0.35%。
NMS

通過觀察 DISK 特徵方法提取出來的特徵點,會存在特徵點密集扎堆的情況,這樣導致的一個後果是部分區域沒有特徵點。
為了緩解這類情況,我們採用比較大半徑的 NMS,利用 NMS 半徑從3擴展到10,從圖上可以反映出來,特徵點扎堆情況得到改善。在 PragueParks 驗證集 Stereo 任務上,也得到0.57%的提升。
Pyramid Descriptor && Guided Pyramid Matching
分析 Corner Cases


在搭建完 baseline 之後,我們在測試集裡面隨機抽樣,選出來部分圖片來分析 corner cases。通過我們觀察,匹配效果不好主要是因為兩種情況,或者同時包含上述兩種情況
- 尺度差距比較大
- 大角度旋轉
針對上述 corener cases,我們採取了金字塔描述子提取和引導匹配策略。

提取不同尺度和不同角度上面基於同一組特徵點提取描述子,也就是特徵點是在一副圖上提取的,描述子根據特徵點的映射到不同圖片上進行提取描述子。
匹配時先設置一個閾值t,如果匹配數量大於閾值t就使用原尺度或者原角度匹配,當小於閾值t時,採用多尺度匹配或者多角度匹配的疊加。
經過修正,上述 corner cases 匹配效果得到一定改善。


經過上述策略在三個數據集驗證集 Stereo 和 Multiview 任務平均提升0.4%。
Retrain SuperGlue
另外我們還重新訓練了SuperGlue,這裡體現在兩個方面。一個是將複現官方的 SuperPoint+SuperGlue 方法。第二個是使用效果更好的特徵提取方法 DISK,訓練 DISK+SuperGlue。其中DISK+SuperGlue 在 YFCC 驗證集上面比官方的 SuperPoint+SuperGlue 高4%左右。
針對比賽數據集,DISK+SuperGlue 在 Phototourism 上表現較好,但在其他另外兩個數據集效果較差,可能是因為 DISK在 Megadepth 上面訓練,在建築物數據集上面過擬合了。而 SuperPoint 是在 COCO 上面訓練的,COCO包含的場景更加豐富,所以泛化能力強一些。
最後在8k賽道(unlimited keypoints),我們對SuperPoint+SuperGlue,DISK+SuperGlue 進行 ensemble,效果比二者單獨使用要更好。
| Methods | Phototourism | PragueParks | GoogleUrban | |||
|---|---|---|---|---|---|---|
| Stereo | Multiview | Stereo | Multiview | Stereo | Multiview | |
| SP-SG(4K) | 0.60357 | 0.78290 | 0.79766 | 0.50499 | 0.41212 | 0.32472 |
| DISK-SG(8K) | 0.61955 ↑ | 0.77531 | 0.72002 | 0.48548 | 0.38764 | 0.26281 |
| SP-DISK-SG | 0.63975 ↑ | 0.78564 ↑ | 0.80700 ↑ | 0.49878 | 0.43952 ↑ | 0.33734 ↑ |
RANSAC && Adapt FH
首先我們嘗試了多種 RANSAC 方法,例如 OpenCV 自帶的 RANSAC 方法,DEGENSAC 方法以及 MAGSAC++方法,通過實驗發現 DEGENSAC 效果最好。
另外 DEGENSAC 使用F矩陣進行求解時,會出現平面退化問題,類似這樣。

針對平面退化問題,受到 ORB-SLAM 的啟發,我們設計了一個自適應 FH 策略,具體算法為:

應用:AR 導航
曠視非常重視將前沿算法與實際業務相結合,本文介紹的 Image Matching 技術已經運用在 S800V SLAM 機器人、AR導航等多個項目之中。
以曠視某“室內視覺定位導航”項目為例,依賴大場景 SfM 稀疏點雲重建技術和 Image Matching 等技術,曠視3D組實現了僅需要使用手機攝像頭,就能在複雜室內場景進行準確定位和 AR 導航的功能。相比於傳統的 GPS、藍牙等室內定位方案,“室內視覺定位導航”具有厘米級建圖精度、亞米級定位精度且無需對室內場景進行額外布點,滿足了客戶對室內定位“高精度、易部署維護”的要求,目前已成功中標若干大型室內場景的室內定位導航項目。
為了讓該技術有更直觀的體驗,室內視覺定位導航APP——“MegGo”已經在礦廠內部上線,支持各個工區的室內定位和導航。即使身處陌生工區,也可以利用這位電子“導遊”,快速準確地導航到會議室等目的地。而來礦廠參觀的小夥伴,也可以在手機上下載MegGo來體驗工區內的定位與導航(下圖分別展示的是使用MegGo進行視覺定位與AR導航)。
[gif-player id="3304"]
視覺定位
[gif-player id="3305"]
AR導航
未來展望
- 在訓練的時候可以加上強化學習,重新訓練整個 pipeline。
- 增強 DISK 的泛化能力,使用更多的數據集進行訓練。
- 使用 Refinements 網絡,進行對特徵點的位置 refine。
參考文獻
1. D. DeTone, T. Malisiewicz, and A. Rabinovich, “SuperPoint: Self-supervised interest point detection and description,”CoRR, vol. abs/1712.07629, 2017.
2. M. Tyszkiewicz, P. Fua, and E. Trulls, “DISK: Learning local features with policy gradient,” Advances in Neural Informa-tion Processing Systems, vol. 33, 2020.
3. K. He, G. Gkioxari, P. Dollár, and R. B. Girshick,“Mask R-CNN,” CoRR, vol. abs/1703.06870, 2017.
4. H. Zhao, J. Shi, X. Qi, X. Wang, and J. Jia, “Pyramid scene parsing network,” in CVPR, 2017.
5. P.-E. Sarlin, D. DeTone, T. Malisiewicz, and A. Rabinovich, “SuperGlue: Learning feature matching with graph neural networks,” in CVPR, 2020.
6. D. Mishkin, J. Matas, and M. Perdoch, “Mods: Fast and robust method for two-view matching,” Computer Vision and Image Understanding, 2015.
7. C. Campos, R. Elvira, J. J. Gomez, J. M. M. Montiel, and J. D.Tardós, “ORB-SLAM3: 一個精確的開源視覺、視覺慣性及多地圖 SLAM 庫,” arXiv preprint arXiv:2007.11898, 2020.