CVPR 2021 Image Matching 挑战赛双冠算法回顾
借之前我们给公司提供的文章,总结一下前一段时间参赛的一些实验和思考。本文版权所有:旷视科技。原文链接:https://www.zhihu.com/question/32066833/answer/2041516754
Image Matching (图像匹配)是计算机视觉领域最基础的技术之一,它是指通过稀疏或者稠密特征匹配的方式,将两幅图像相同位置的局部信息进行关联。Image Matching 在很多领域均有广泛应用,比如机器人、无人车、AR/VR、图像/商品检索、指纹识别等等。
在今年刚刚结束的 CVPR 2021 Image Matching 比赛中,旷视 3D 组获得两冠一亚的成绩,本文介绍了他们的比赛方案、实验和一些思考。



比赛介绍
图像匹配是指将两幅图像具有相同或者相似属性的内容或结构进行像素上的识别与对齐。一般而言,待匹配的图像通常取自相同或相似的场景或目标,或者具有相同形状或语义信息的其他类型的图像对,从而具有一定的可匹配性。
Image Matching Challenge

本次 Image Matching Challenge(IMC) 比赛还是分为两个赛道 unlimited keypoints 和 restricted keypoints,即每张图片可提取特征点数量分别小于 8k 和 2k。
今年 IMC 比赛一共有三个数据集,分别是 Phototourism、PragueParks 和 GoogleUrban ,这三个数据集差异比较大,对算法的泛化能力要求比较高。主办方希望找到一种方法在三个数据集上面表现都比较好的方法,所以最终排名是这三个数据集排名的平均。
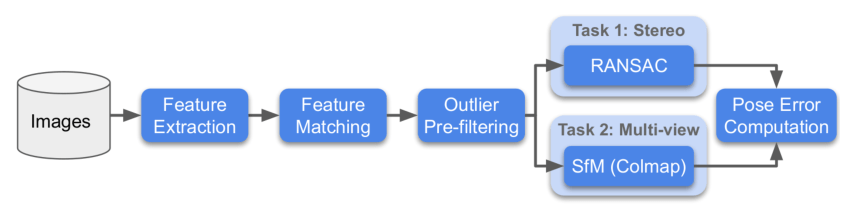
针对每个数据集,主办方会采用两种方法进行评估,分别是 Stereo 和 Multiview,然后分别求这两个任务 rank。
- Stereo:通过两张图片进行匹配,然后解算F矩阵,求解实际的位姿误差。
- Multiview:选取少部分图片组成一个bags,通过bags进行建图,通过3d模型求解不同图片之间的位姿误差。
下面为比赛流程图:
SimLoc Match

SimLoc 也是包含不同场景的数据集,与 IMC 数据集不同之处是一个合成数据集,可以获得完全准确的ground truth。
比赛有三个指标,最终使用匹配成功率当做最终的排名评测指标,三个指标分别是:
- 内点数量(越高越好)
- 匹配成功率,即匹配内点数量/所有提供的匹配对(越高越好)
- 负匹配对数量,当两张图片没有共视区域时,匹配对应该越少越好
方案
数据分析


首先对比赛的三个数据集进行分析
- 观察验证集和测试集之间是否存在gap
- 通过统计各个数据集之间的长宽,来确定resize的大小
Pipeline
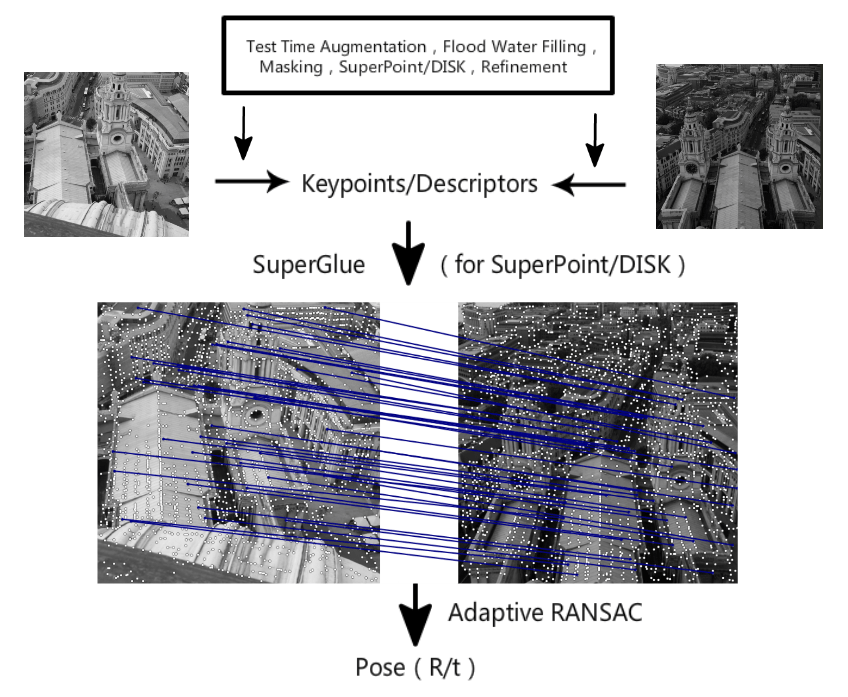
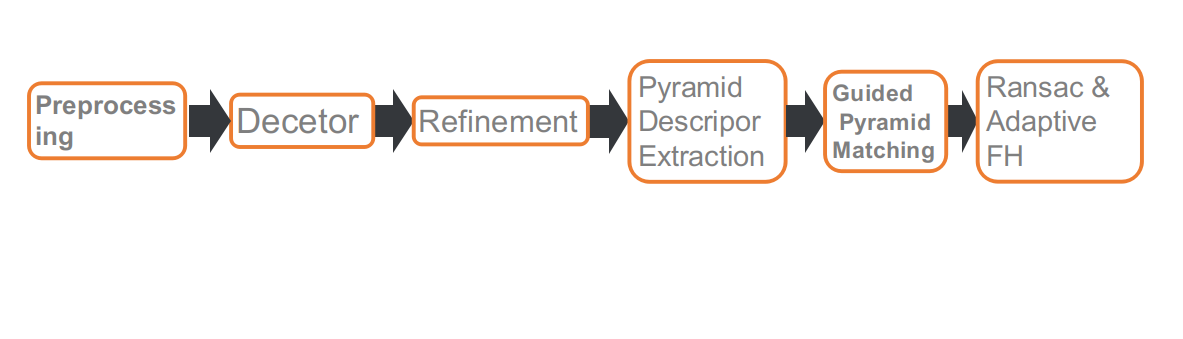
这是我们比赛的pipeline,一共包含六个部分。分别是:预处理,特征点检测,refine特征点位置,多尺度或者多角度提取描述子,Guided 匹配和基于自适应FH的RANSAC。
预处理


IMC 赛道对特征点数量有限制,所以特征点的位置就比较重要,一些动态的物体比如行人,车辆,天空等等。对匹配求解位姿没有作用,或者有负面作用。所以我们采用分割网络将这些物体给 mask 掉,当提取特征点的时候,会略过 mask 区域。
使用分割网络进行预处理之后,我们发现了两个问题。
- 一个是由于分割网络的精确度不高,并不能很好的区分建筑物和天空连接区域,会存在一些把建筑物边缘破坏掉情况,这样不利于匹配。所以我们 mask 动态物体之后,对 mask 区域做了一个腐蚀处理,这样可以把建筑物的边缘细节给保留下来。
- 另外一个问题是分割网络算法针对真人和雕塑的泛化能力不是很好,当 mask 行人的时候,也会把雕塑给mask掉。而部分场景例如林肯数据集,雕塑上面的特征点对匹配结果比较重要。针对这个情况,我们训练了一个分类网络来区分雕塑和行人,这样既可以去掉行人又可以保留下来雕塑。
通过预处理操作,在 Phototourism 验证集 Stereo 和 Multiview 任务分别提升1.1%和0.3%。
特征点提取
Adapt Homographic
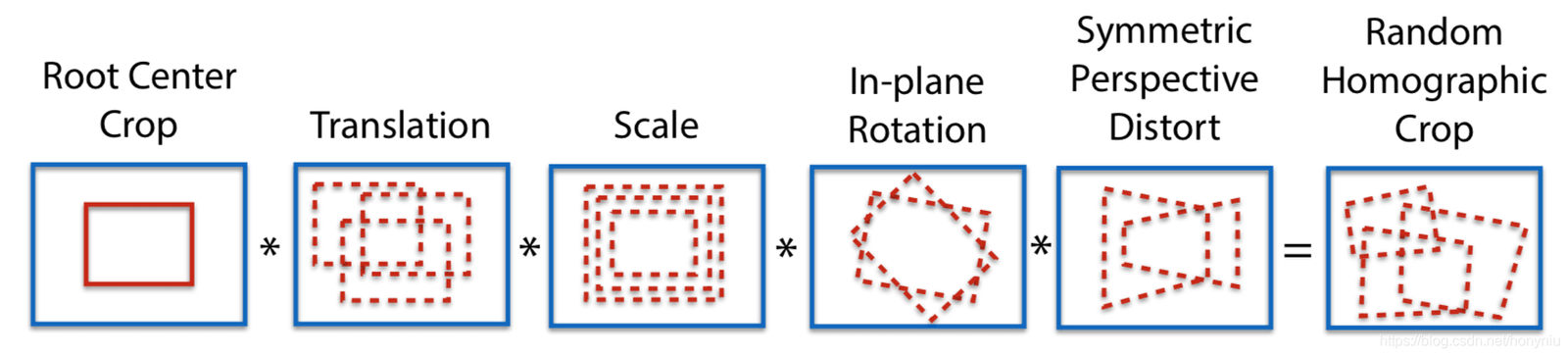
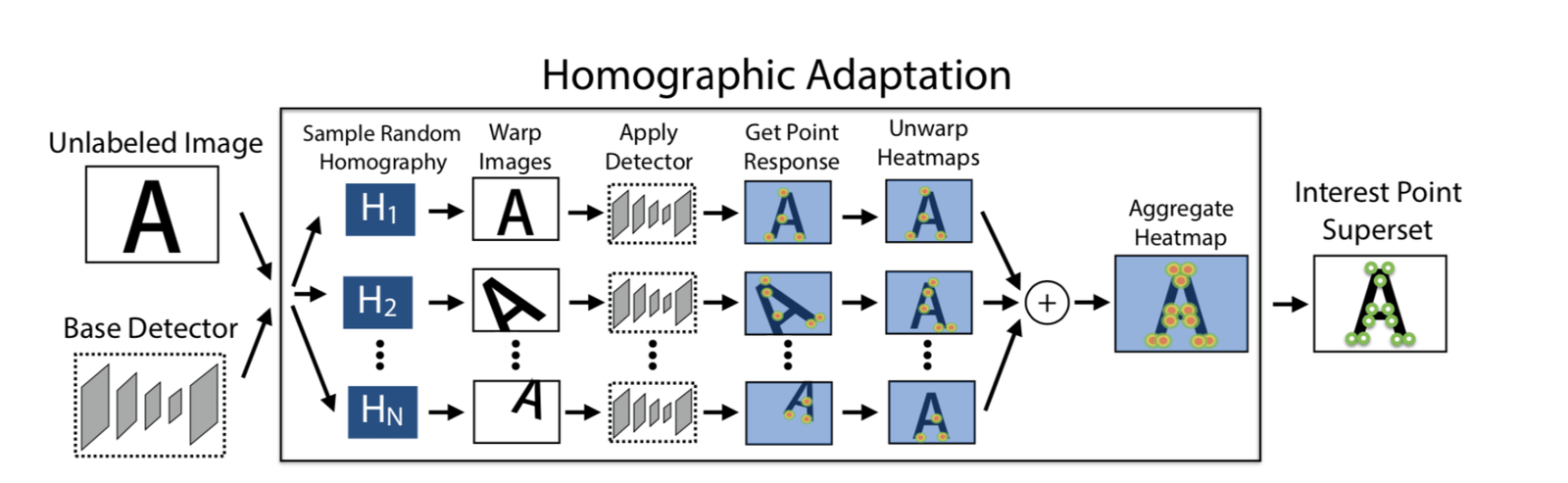
采用100次单应矩阵变换,得到100张变换后的图像,在这些图像上利用 SuperPoint 模型分别提取特征点,可以得到n个特征点的 heatmap,把这n个 heatmap 叠加到一些,得到最后的heatmap,然后再根据需要选择特征点。这样做的好处一个是可以提取更多的特征点,第二个是特征点的位置也会更加合理一些。
通过使用 Adapt Homographic,在 Phototourism 验证集 Stereo 和 Multiview 任务分别提升1.7%和1.3%。
Refinement
SuperPoint 提取出来的特征点是整数,我们采用 soft argmax refinement 并且使用半径为2的参数,进行亚像素化,使得特征点位置更加准确。采用 refinement 方法,在 Phototourism 验证集 Stereo 和 Multiview 任务分别提升0.8%和0.35%。
NMS

通过观察 DISK 特征方法提取出来的特征点,会存在特征点密集扎堆的情况,这样导致的一个后果是部分区域没有特征点。
为了缓解这类情况,我们采用比较大半径的 NMS,利用 NMS 半径从3扩展到10,从图上可以反映出来,特征点扎堆情况得到改善。在 PragueParks 验证集 Stereo 任务上,也得到0.57%的提升。
Pyramid Descriptor && Guided Pyramid Matching
分析 Corner Cases


在搭建完 baseline 之后,我们在测试集里面随机抽样,选出来部分图片来分析 corner cases。通过我们观察,匹配效果不好主要是因为两种情况,或者同时包含上述两种情况
- 尺度差距比较大
- 大角度旋转
针对上述 corener cases,我们采取了金字塔描述子提取和引导匹配策略。

提取不同尺度和不同角度上面基于同一组特征点提取描述子,也就是特征点是在一副图上提取的,描述子根据特征点的映射到不同图片上进行提取描述子。
匹配时先设置一个阈值t,如果匹配数量大于阈值t就使用原尺度或者原角度匹配,当小于阈值t时,采用多尺度匹配或者多角度匹配的叠加。
经过修正,上述 corner cases 匹配效果得到一定改善。


经过上述策略在三个数据集验证集 Stereo 和 Multiview 任务平均提升0.4%。
Retrain SuperGlue
另外我们还重新训练了SuperGlue,这里体现在两个方面。一个是将复现官方的 SuperPoint+SuperGlue 方法。第二个是使用效果更好的特征提取方法 DISK,训练 DISK+SuperGlue。其中DISK+SuperGlue 在 YFCC 验证集上面比官方的 SuperPoint+SuperGlue 高4%左右。
针对比赛数据集,DISK+SuperGlue 在 Phototourism 上表现较好,但在其他另外两个数据集效果较差,可能是因为 DISK在 Megadepth 上面训练,在建筑物数据集上面过拟合了。而 SuperPoint 是在 COCO 上面训练的,COCO包含的场景更加丰富,所以泛化能力强一些。
最后在8k赛道(unlimited keypoints),我们对SuperPoint+SuperGlue ,DISK+SuperGlue 进行 ensemble,效果比二者单独使用要更好。
| Methods | Phototourism | PragueParks | GoogleUrban | |||
|---|---|---|---|---|---|---|
| Stereo | Multiview | Stereo | Multiview | Stereo | Multiview | |
| SP-SG(4K) | 0.60357 | 0.78290 | 0.79766 | 0.50499 | 0.41212 | 0.32472 |
| DISK-SG(8K) | 0.61955 ↑ | 0.77531 | 0.72002 | 0.48548 | 0.38764 | 0.26281 |
| SP-DISK-SG | 0.63975 ↑ | 0.78564 ↑ | 0.80700 ↑ | 0.49878 | 0.43952 ↑ | 0.33734 ↑ |
RANSAC && Adapt FH
首先我们尝试了多种 RANSAC 方法,例如 OpenCV 自带的 RANSAC 方法,DEGENSAC 方法以及 MAGSAC++方法,通过实验发现 DEGENSAC 效果最好。
另外 DEGENSAC 使用F矩阵进行求解时,会出现平面退化问题,类似这样。

针对平面退化问题,受到 ORB-SLAM 的启发,我们设计了一个自适应 FH 策略,具体算法为:

应用:AR 导航
旷视非常重视将前沿算法与实际业务相结合,本文介绍的 Image Matching 技术已经运用在 S800V SLAM 机器人、AR导航等多个项目之中。
以旷视某“室内视觉定位导航”项目为例,依赖大场景 SfM 稀疏点云重建技术和 Image Matching 等技术,旷视3D组实现了仅需要使用手机摄像头,就能在复杂室内场景进行准确定位和 AR 导航的功能。相比于传统的 GPS、蓝牙等室内定位方案,“室内视觉定位导航”具有厘米级建图精度、亚米级定位精度且无需对室内场景进行额外布点,满足了客户对室内定位“高精度、易部署维护”的要求,目前已成功中标若干大型室内场景的室内定位导航项目。
为了让该技术有更直观的体验,室内视觉定位导航APP——“MegGo”已经在矿厂内部上线,支持各个工区的室内定位和导航。即使身处陌生工区,也可以利用这位电子“导游”,快速准确地导航到会议室等目的地。而来矿厂参观的小伙伴,也可以在手机上下载MegGo来体验工区内的定位与导航(下图分别展示的是使用MegGo进行视觉定位与AR导航)。
[gif-player id="3304"]
视觉定位
[gif-player id="3305"]
AR导航
未来展望
- 在训练的时候可以加上强化学习,重新训练整个 pipeline。
- 增强 DISK 的泛化能力,使用更多的数据集进行训练。
- 使用 Refinements 网络,进行对特征点的位置 refine。
参考文献
1. D. DeTone, T. Malisiewicz, and A. Rabinovich, “SuperPoint: Self-supervised interest point detection and description,”CoRR, vol. abs/1712.07629, 2017.
2. M. Tyszkiewicz, P. Fua, and E. Trulls, “DISK: Learning local features with policy gradient,” Advances in Neural Informa-tion Processing Systems, vol. 33, 2020.
3. K. He, G. Gkioxari, P. Dollár, and R. B. Girshick,“Mask R-CNN,” CoRR, vol. abs/1703.06870, 2017.
4. H. Zhao, J. Shi, X. Qi, X. Wang, and J. Jia, “Pyramid scene parsing network,” in CVPR, 2017.
5. P.-E. Sarlin, D. DeTone, T. Malisiewicz, and A. Rabinovich, “SuperGlue: Learning feature matching with graph neural networks,” in CVPR, 2020.
6. D. Mishkin, J. Matas, and M. Perdoch, “Mods: Fast and robust method for two-view matching,” Computer Vision and Image Understanding, 2015.
7. C. Campos, R. Elvira, J. J. Gomez, J. M. M. Montiel, and J. D.Tardós, “ORB-SLAM3: An accurate open-source library for visual, visual-inertial and multi-map SLAM,” arXiv preprint arXiv:2007.11898, 2020.
赞!一直在关注visual localization领域的进展,其中 image matching 相当重要。就我了解,近两年 image matching算法基本被superpoint+superglue 统治,不少工作基于此进行改进,本文方法效果也是非常棒!去年商汤的loftr匹配做的不错,但用作定位精度提升并不显著。请问作者,image matching未来的发展趋势如何?此外visual localization作为一个系统工程,其中的几个步骤(构建精准的视觉地图,image retrieval, image matching, pose estimation)中最为挑战以及能够提升定位精度的手段可以有哪些?感谢!
从我们实践经验看,各种不同 Local Feature 虽然文章中差异很大但实际场景差异都不大。现在的 Pipeline 里面最关键的 SuperGlue 这种 Matching 能够调好(基本要看重新复现的能力),其次是各种全局描述用各种策略来保证相似场景的正确率。
未来我认为提升精度靠的就是 Feature Matric 类的技术做 Refine,例如稀疏的 PixLoc 或者稠密的可微渲染。