論文筆記:NeRF: 以神經輻射場表示場景以進行視圖合成
NeRF 是 ECCV 2020 的 Oral,影響非常大,可以說從基礎上創造出了新的基於神經網絡隱式表達來重建場景的路線。由於其簡潔的思想和完美的效果,至今仍然有非常多的 3D 相關工作以此為基礎。
NeRF 所做的任務是 Novel View Synthesis(新視角合成),即在若干已知視角下對場景進行一系列的觀測(相機內外參、圖像、Pose 等),合成任意新視角下的圖像。傳統方法中,通常這一任務採用三維重建再渲染的方式實現,NeRF 希望不進行顯式的三維重建過程,僅根據內外參直接得到新視角渲染的圖像。為了實現這一目的,NeRF 使用用神經網絡作為一個 3D 場景的隱式表達,代替傳統的點雲、網格、體素、TSDF 等方式,通過這樣的網絡可以直接渲染任意角度任意位置的投影圖像。

NeRF 的思想比較簡單,就是通過輸入視角的圖像每個像素的射線對於密度(不透明度)積分進行體素渲染,然後通過該像素渲染的 RGB 值與真值進行對比作為 Loss。由於文中設計的體素渲染是完全可微的,因此該網絡可學習:
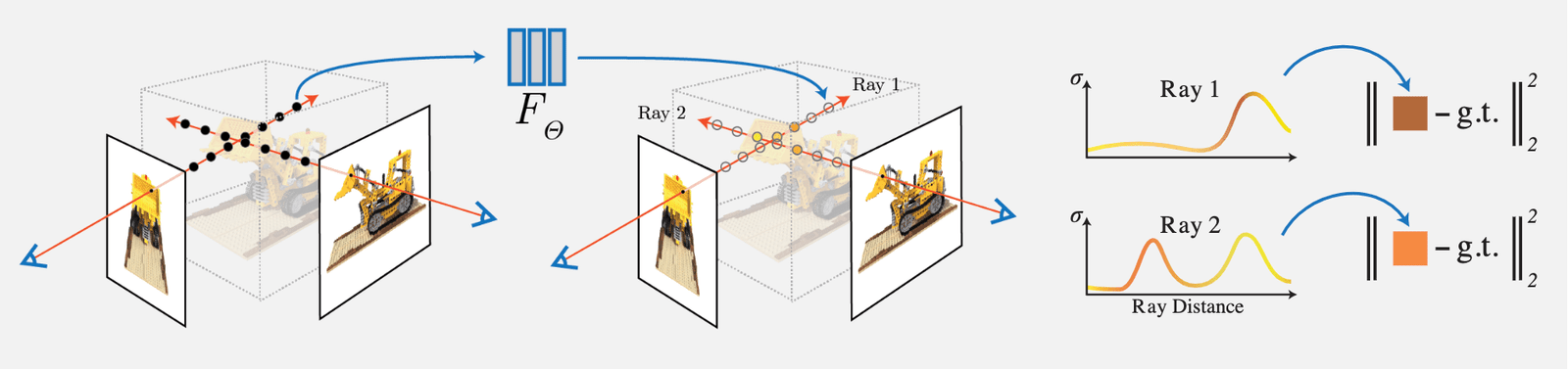
其主要工作和創新點如下:
1)提出一種用 5D 神經輻射場 (Neural Radiance Field) 來表達複雜的幾何+材質連續場景的方法,該輻射場使用 MLP 網絡進行參數化;
2)提出一種基於經典體素渲染 (Volume Rendering) 改進的可微渲染方法,能夠通過可微渲染得到 RGB 圖像,並將此作為優化的目標。該部分包含採用分層採樣的加速策略,來將 MLP 的容量分配到可見的內容區域;
3)提出一種位置編碼 (Position Encoding) 方法將每個 5D 坐標映射到更高維的空間,這樣使得我們可以讓我們優化神經輻射場更好地表達高頻細節內容。

1 Neural Radiance Field Scene Representation (基於神經輻射場的場景表示)
NeRF 將一個連續的場景表示為一個 5D 向量值函數(vector-valued function),其中:
- 輸入為:3D 位置 \mathbf{x}=(x, y, z) 和 2D 視角方向 (\theta, \phi)
- 輸出為:發射顏色 \mathbf{c}=(r, g, b) 和體積密度(不透明度) \sigma。
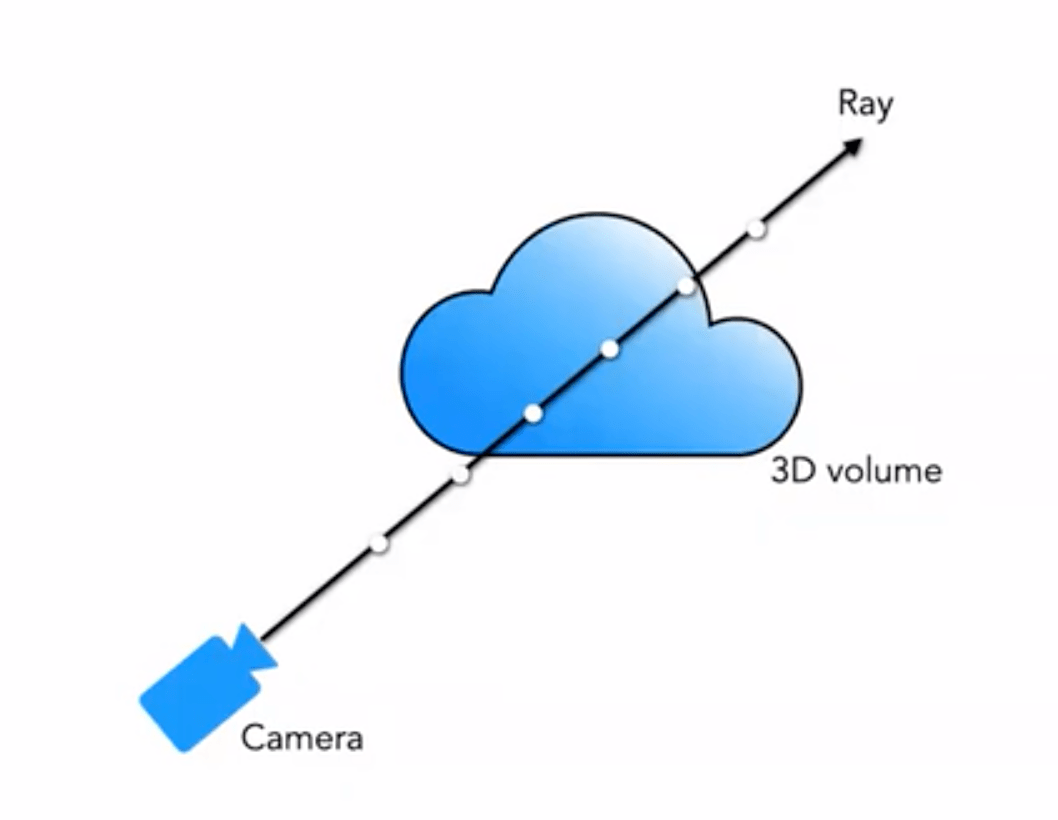
對於其中的 2D 視角方向可以用下圖進行直觀解釋:
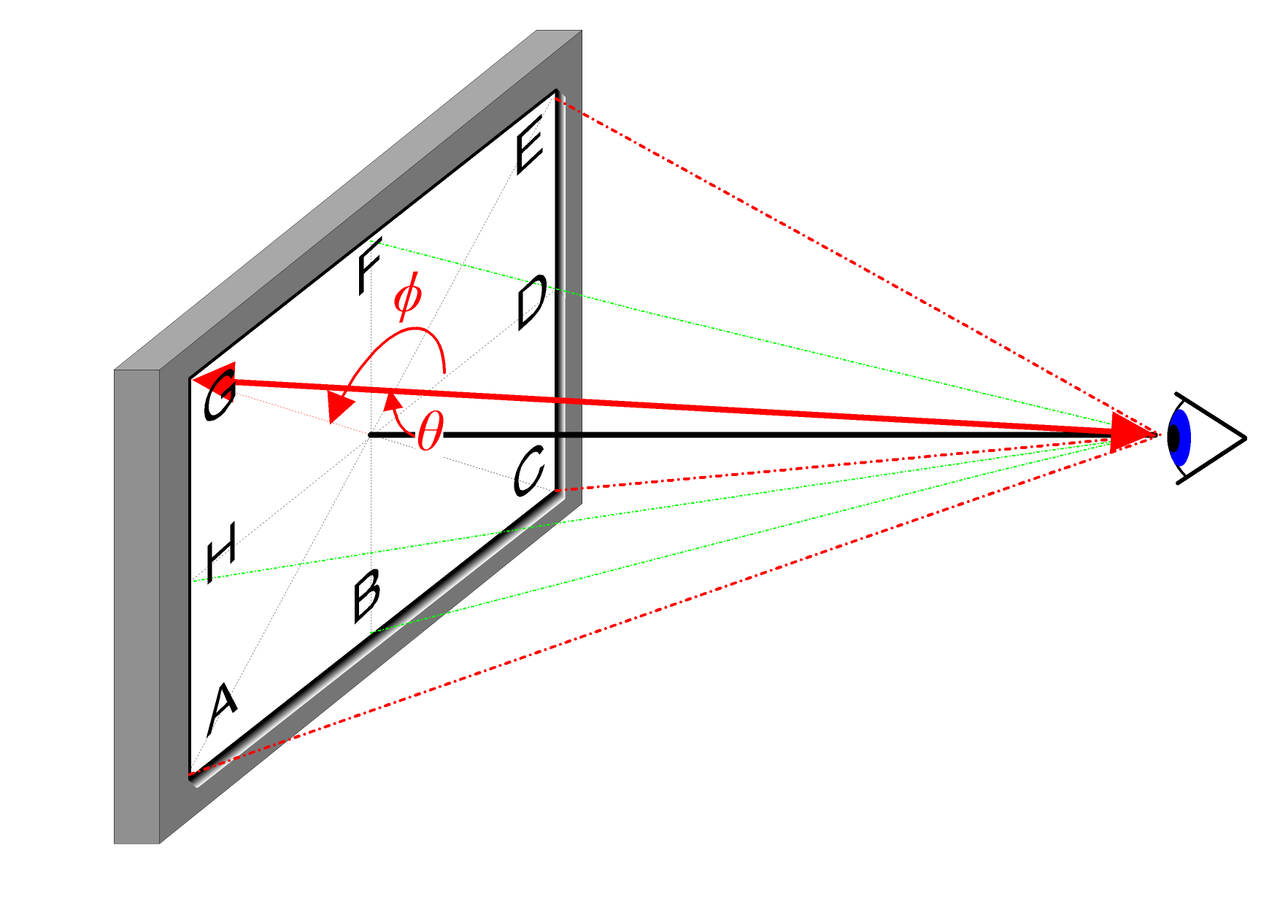
在實際實現中,視角方向表示為一個三維笛卡爾坐標系單位向量 \mathbf{d},也就是圖像中的任意位置與相機光心的連線,我們用一個 MLP 全連接網絡表示這種映射:
\begin{equation}F_{\Theta}:(\mathbf{x}, \mathbf{d}) \rightarrow(\mathbf{c}, \sigma)\end{equation}
通過優化這樣一個網絡的參數 \Theta 來學習得到這樣一個 5D 坐標輸入到對應顏色和密度輸出的映射。
為了讓網絡學習到多視角的表示,我們有如下兩個合理假設:
- 體積密度(不透明度) \sigma 只與三維位置 \mathbf{x} 有關而與視角方向 \mathbf{d} 無關。物體不同位置的密度應該和觀察角度無關,這一點比較顯然。
- 顏色 \mathbf{c} 與三維位置 \mathbf{x} 和視角方向 \mathbf{d} 都相關。
預測體積密度 \sigma 的網絡部分輸入僅僅是輸入位置 \mathbf{x},而預測顏色 \mathbf{c} 的網絡輸入是視角和方向 \mathbf{d}。在具體實現上:
- MLP 網絡 F_{\Theta} 首先用 8 層的全連接層(使用 ReLU 激活函數,每層有 256 個通道),處理 3D 坐標 \mathbf{x},得到 \sigma 和一個 256 維的特徵向量。
- 將該 256 維的特徵向量與視角方向 \mathbf{d} 與視角方向一起拼接起來,餵給另一個全連接層(使用 ReLU 激活函數,每層有 128 個通道),輸出方向相關的 RGB 顏色。
本文中一個示意的網絡結構如下:


Fig 3 展示了我們的網絡可以表示出非朗伯體效應(non-Lambertian effects);Fig 4 展示了如果訓練時沒有視角 (View Dependence) 的輸入(只有 \mathbf{x}),則網絡無法表示高光效果。

2 Volume Rendering with Radiance Fields (基於輻射場的體素渲染)
2.1 經典渲染方程
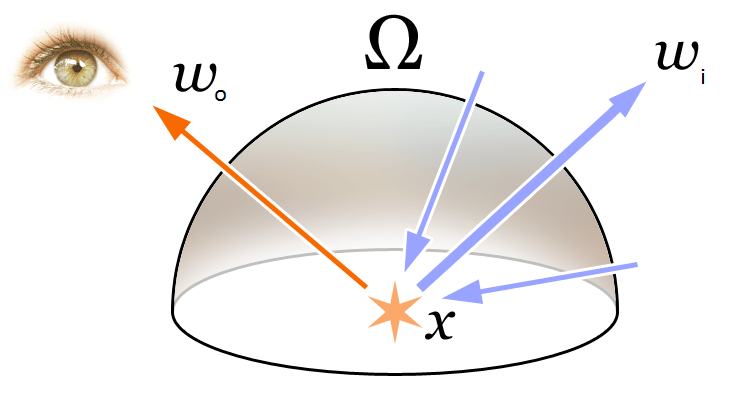
為了理解文中的 Volume Rendering 和 Radiance Field 的概念首先我們回顧下圖形學中最基礎的渲染方程:
\begin{equation}\begin{array}{l}L_{o}(\boldsymbol{x}, \boldsymbol{d}) &=L_{e}(\boldsymbol{x}, \boldsymbol{d})+\int_{\Omega} f_{r}\left(\boldsymbol{x}, \boldsymbol{d}, \boldsymbol{\omega}_{i}\right) L_{i}\left(\boldsymbol{x}, \boldsymbol{\omega}_{i}\right) \left(\boldsymbol{\omega}_{i}, \boldsymbol{n}\right) d \boldsymbol{\omega}_{i}\\&=L_{e}(\boldsymbol{x}, \boldsymbol{d})+\int_{\Omega} f_{r}\left(\boldsymbol{x}, \boldsymbol{d}, \boldsymbol{\omega}_{i}\right) L_{i}\left(\boldsymbol{x}, \boldsymbol{\omega}_{i}\right) \cos \theta d \boldsymbol{\omega}_{i}\end{array}\end{equation}
如上圖所示,渲染方程表達了 3D 空間位置 \mathbf{x} 在方向 \mathbf{d} 的輻射(出射光) L_{o}(\boldsymbol{x}, \boldsymbol{d})。該輻射表達為該點自身向外的輻射(發射光)L_{e}(\boldsymbol{x}, \boldsymbol{d}) 和該點反射外界的輻射(反射光)之和。具體說來:
- L_{e}(\boldsymbol{x}, \boldsymbol{d}) 表示 \mathbf{x} 為光源點在方向 \mathbf{d} 釋放的輻射(發射光)
- \int_{\Omega} f_{r}\left(\boldsymbol{x}, \boldsymbol{d}, \boldsymbol{\omega}_{i}\right) L_{i}\left(\boldbold \sin \left(2^{L-1} \pi p\right), \cos \left(2^{L-1} \pi p\right)\right)\end{equation}
該函數 \gamma(\cdot) 會應用於三維位置坐標 \mathbf{x} (歸一化到 [-1, 1])和三維視角方向笛卡爾坐標 \mathbf{d}。在本文中對於 \gamma(\mathbf{x}) 設置 L=10;對於\gamma(\mathbf{d}) 設置 L=4。
因此可以得到對於三維位置坐標的編碼長度為:3 \times 2 \times 10 = 60,對於三維視角方向的位置編碼為 3 \times 2 \times 4 = 24,與網絡結構圖上的輸入維度相對應。
相似地,在 Transformer 中也有一個類似的位置編碼操作,不過本文中與其還是根本不同。在 Transformer 中位置編碼是用來表示輸入的序列信息的,而這裡的位置編碼是做用於輸入將輸入映射到高維從而讓網絡能夠更好地學習到高頻信息。
3.2 Hierarchical Sampling Procedure (分層採樣方案)
分層採樣方案來自於經典渲染算法的加速工作,在前述的體素渲染 (Volume Rendering) 方法中,對於射線上的點如何採樣會影響最終的效率,如果採樣點過多計算效率太低,採樣點過少又不能很好地近似。那麼一個很自然的想法就是希望對於顏色貢獻大的點附近採樣密集,貢獻小的點附近採樣稀疏,這樣就可以解決問題。基於這一想法,NeRF 很自然地提出由粗到細的分層採樣方案(Coarse to Fine)。

Coarse 部分:首先對於粗網絡,我們採樣 N_c 個稀疏點(c 表示 Coarse),並將公式 (3) 用新的形式修改(加入權重):
\begin{equation}\hat{C}_{c}(\mathbf{r})=\sum_{i=1}^{N_{c}} w_{i} c_{i}, \quad w_{i}=T_{i}\left(1-\exp \left(-\sigma_{i} \delta_{i}\right)\right)\end{equation}
其中權重需要進行歸一化:
\begin{equation}\hat{w}_{i}=\frac{w_{i}}{\sum_{j=1}^{N_{c}} w_{j}}\end{equation}這裡面的權重 \hat{w}_{i} 可以看成沿著射線的分段常數概率密度函數 (Piecewise-constant PDF)。通過這個概率密度函數可以粗略地得到射線上物體的分佈情況。

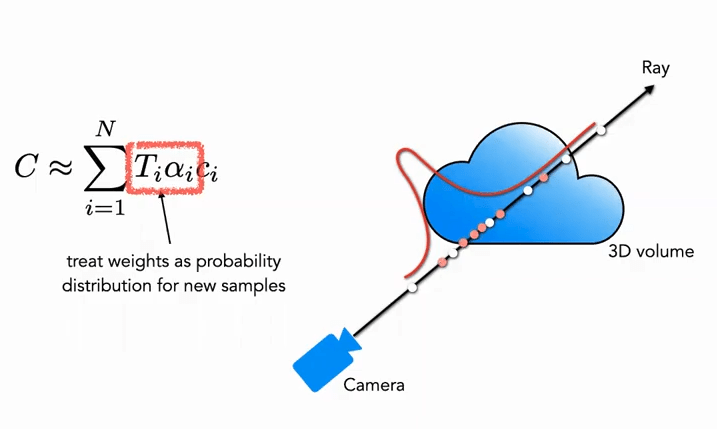
Fine 部分:在第二階段,我們使用逆變換採樣 (Inverse Transform Sampling),根據上面的分佈採樣出第二個集合 N_f,最終我們仍然使用公式 (3) 來計算 \hat{C}_{f}(\mathbf{r})。但不同的是使用了全部的 N_c + N_f 個樣本。使用這種方法,第二次採樣可以根據分佈採樣更多的樣本在真正有場景內容的區域,實現了重要性抽樣 (Importance Sampling)。
如圖所示,白色點為第一次均勻採樣的點,通過白色均勻採樣後得到的分佈,第二次再根據分佈對進行紅色點採樣,概率高的地方密集,概率低的地方稀疏 (很像粒子濾波)。
3.3 Implementation Details (實現細節)
在訓練損失函數方面,本文的定義非常簡單直接,就是對於粗網絡和精網絡都用渲染的 L_2 Loss,公式如下:
\begin{equation}\mathcal{L}=\sum_{\mathbf{r} \in \mathcal{R}}\left[\left\|\hat{C}_{c}(\mathbf{r})-C(\mathbf{r})\right\|_{2}^{2}+\left\|\hat{C}_{f}(\mathbf{r})-C(\mathbf{r})\right\|_{2}^{2}\right]\end{equation}其中:
- \mathcal{R} 表示一個 batch 中的所有採樣的射線集合
- C(\mathbf{r}) 表示真值的 RGB 顏色
- \hat{C}_{c}(\mathbf{r}) 表示 Coarse 網絡預測的 RGB 顏色
- \hat{C}_{f}(\mathbf{r}) 表示 Fine 網絡預測的 RGB 顏色
4 Results (實驗結果)
本文對比了很多相關的工作例如:
- Neural Volumes (NV):https://github.com/facebookresearch/neuralvolumes
- Scene Representation Networks (SRN):https://github.com/vsitzmann/scene-representation-networks
- Local Light Field Fusion (LLFF):https://github.com/Fyusion/LLFF
4.1 Datasets (數據集)
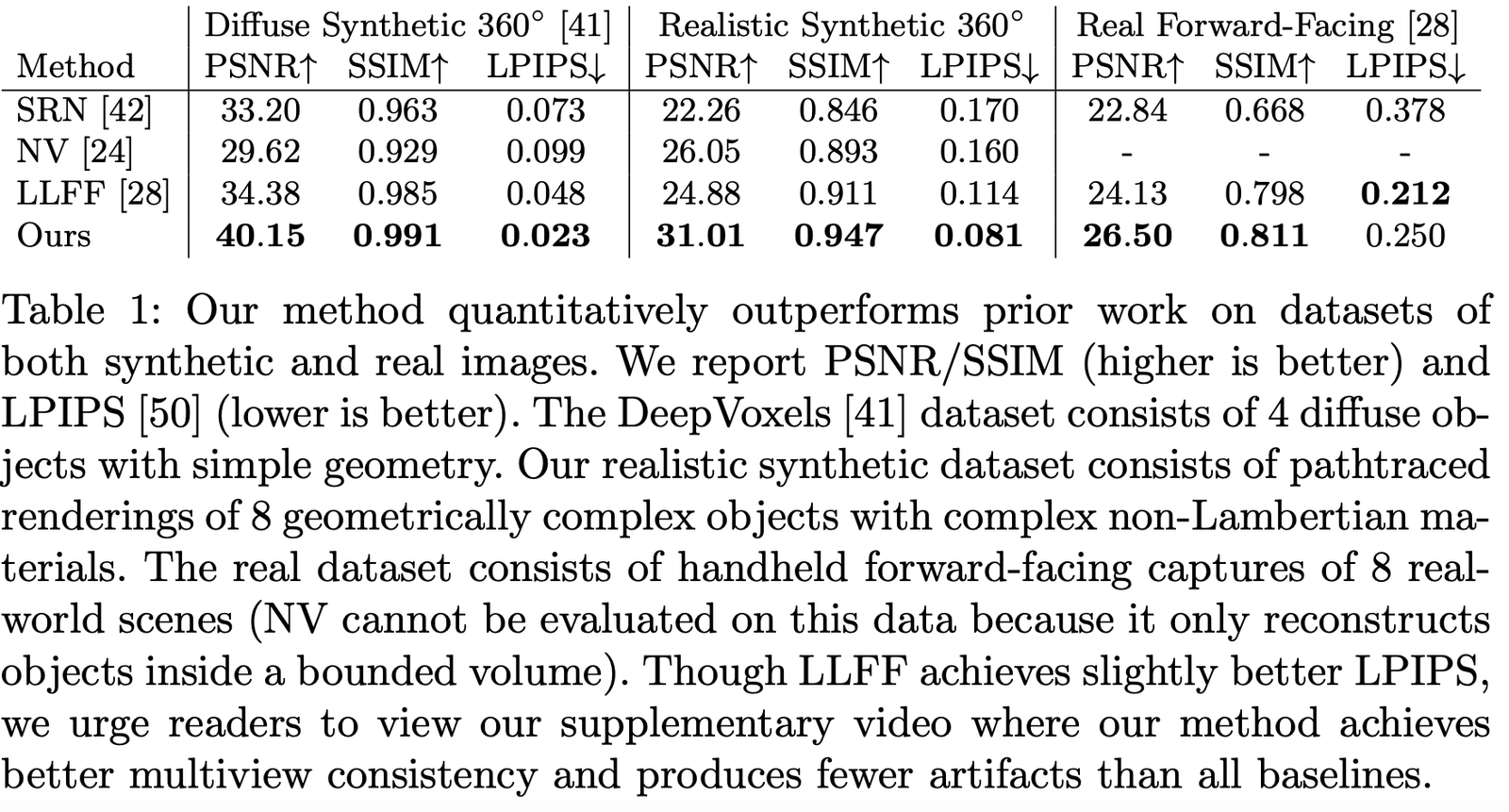
作者對比了在不同數據集中的表現,可以看出基本上所有數據集上都是遙遙領先的:

在仿真數據集上的可視化效果:

在真實數據集上的可視化效果:
4.2 Ablation Studies (消融實驗)
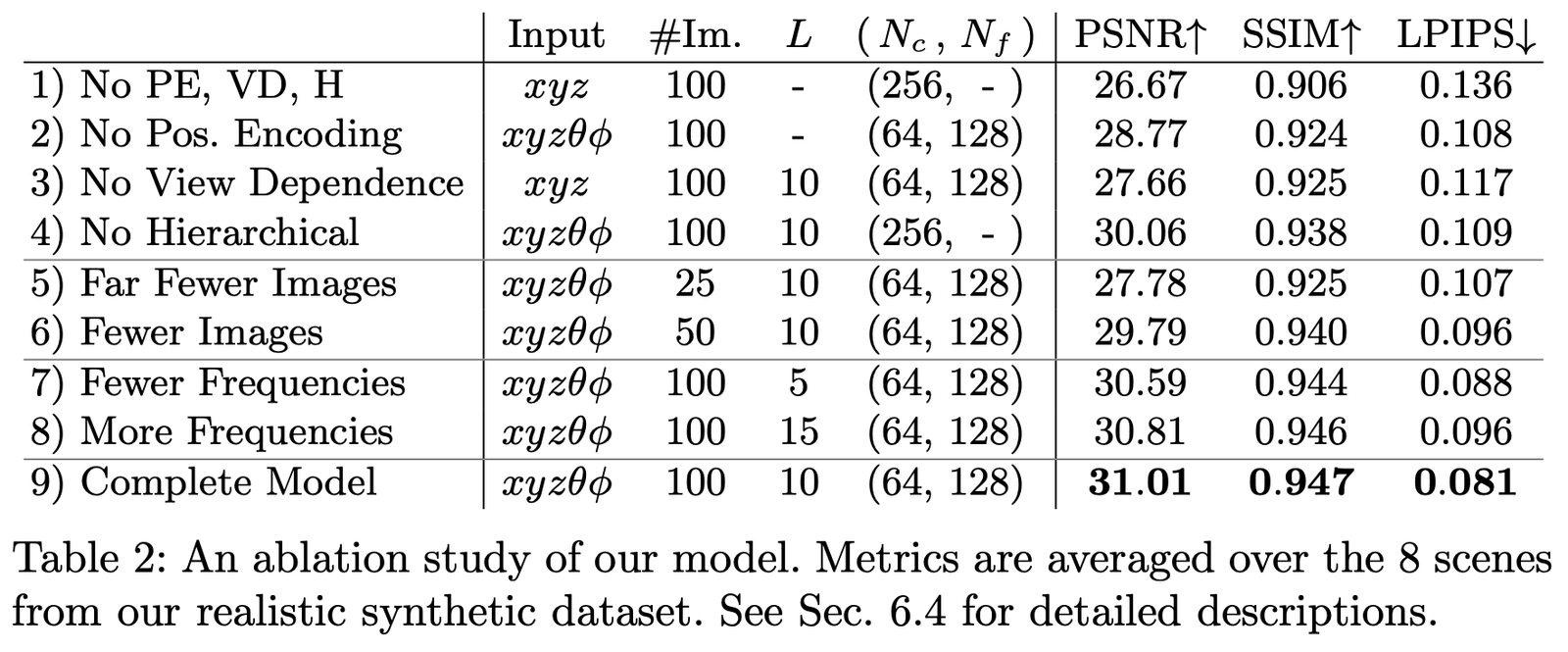
我們在數據集 Realistic Synthetic 360◦ 上進行了不同參數和設置下的消融實驗,結果如下:

主要對比的是如下幾個設置:
- Positional encoding (PE),即 \mathbf{x}
- View Dependence (VD),即 \mathbf{d}
- Hierarchical sampling (H)
其中:
第1行表示不包含以上任何一個部分的最小網絡;
第2-4行表示每次分別去掉一個部分;
第5-6行表示樣本圖像更少時的效果差異;
第7-8行表示頻率 L (也就是位置編碼 \mathbf{x} 的頻率展開級別)設置不同时的效果差異。論文小結
本文最大的創新點就是通過隱式表達繞過了人工設計三維場景表示的方法,能夠從更高維度學習到場景的三維信息。但缺點是速度非常慢,這一點在後續很多工作也有改進。另一方面本文的可解釋性,隱式表達的能力,依然需要更多工作來探索。
但歸根結底,相信這樣簡潔有效的方式,未來會成為 3D 和 4D 場景重建的革命點,給三維視覺帶來新的爆發。論文下載
PDF | Website | Code (Official) | Code (Pytorch Lightning) | Recording | Recording (Bilibili)
Colab Example:Tiny NeRF | Full NeRF參考材料
[1] Mildenhall B, Srinivasan P P, Tancik M, et al. Nerf: Representing scenes as neural radiance fields for view synthesis[C]//European Conference on Computer Vision. Springer, Cham, 2020: 405-421.
[2] https://www.cnblogs.com/noluye/p/14547115.html
[3] https://www.cnblogs.com/noluye/p/14718570.html
[4] https://github.com/yenchenlin/awesome-NeRF
[5] https://zhuanlan.zhihu.com/p/360365941
[6] https://zhuanlan.zhihu.com/p/380015071
[7] https://blog.csdn.net/ftimes/article/details/105890744
[8] https://zhuanlan.zhihu.com/p/384946242
[9] https://zhuanlan.zhihu.com/p/386127288
[10] https://blog.csdn.net/g11d111/article/details/118959540
[11] https://www.bilibili.com/video/BV1fL4y1T7Ag
[12] https://zh.wikipedia.org/wiki/%E6%B8%B2%E6%9F%93%E6%96%B9%E7%A8%8B
[13] https://zhuanlan.zhihu.com/p/380015071
[14] https://blog.csdn.net/soaring_casia/article/details/117664146
[15] https://www.youtube.com/watch?v=Al6NTbgka1o
[16] https://github.com/matajoh/fourier_feature_nets相關工作
DSNeRF:https://github.com/dunbar12138/DSNeRF (SfM 加速 NerF)
BARF:https://github.com/chenhsuanlin/bundle-adjusting-NeRF
PlenOctrees:https://alexyu.net/plenoctrees/ (使用 PlenOctrees 加速 NeRF 渲染)
https://github.com/google-research/google-research/tree/master/jaxnerf (使用 JAX 實現加快訓練速度)