논문 노트: NeRF: 신경 방사 필드로 장면을 표현하여 뷰 합성
NeRF는 ECCV 2020의 Oral로, 매우 큰 영향을 미쳤으며, 신경망 기반의 암묵적 표현을 통해 장면을 재구성하는 새로운 경로를 근본적으로 창조했다고 할 수 있습니다. 그 간결한 아이디어와 완벽한 효과 덕분에, 여전히 많은 3D 관련 작업들이 이를 기반으로 하고 있습니다.
NeRF가 수행하는 작업은 Novel View Synthesis(새로운 시점 합성)으로, 여러 알려진 시점에서 장면을 관찰(카메라의 내부 및 외부 파라미터, 이미지, 포즈 등)하고, 임의의 새로운 시점에서 이미지를 합성하는 것입니다. 전통적인 방법에서는 이 작업을 3D 재구성 후 렌더링하는 방식으로 구현했지만, NeRF는 명시적인 3D 재구성 과정을 거치지 않고, 내부 및 외부 파라미터만으로 새로운 시점에서의 렌더링 이미지를 직접 얻고자 합니다. 이를 위해 NeRF는 신경망을 3D 장면의 암묵적 표현으로 사용하여, 전통적인 점군, 메쉬, 복셀, TSDF 등의 방식을 대체하고, 이러한 네트워크를 통해 임의의 각도와 위치에서 투영된 이미지를 직접 렌더링할 수 있습니다.

NeRF의 아이디어는 비교적 간단합니다. 입력 시점의 이미지에서 각 픽셀의 광선을 밀도(불투명도)에 대해 적분하여 복셀 렌더링을 수행한 후, 해당 픽셀의 렌더링된 RGB 값과 실제 값을 비교하여 Loss로 사용합니다. 문서에서 설계된 복셀 렌더링은 완전히 미분 가능하므로, 이 네트워크는 학습할 수 있습니다:
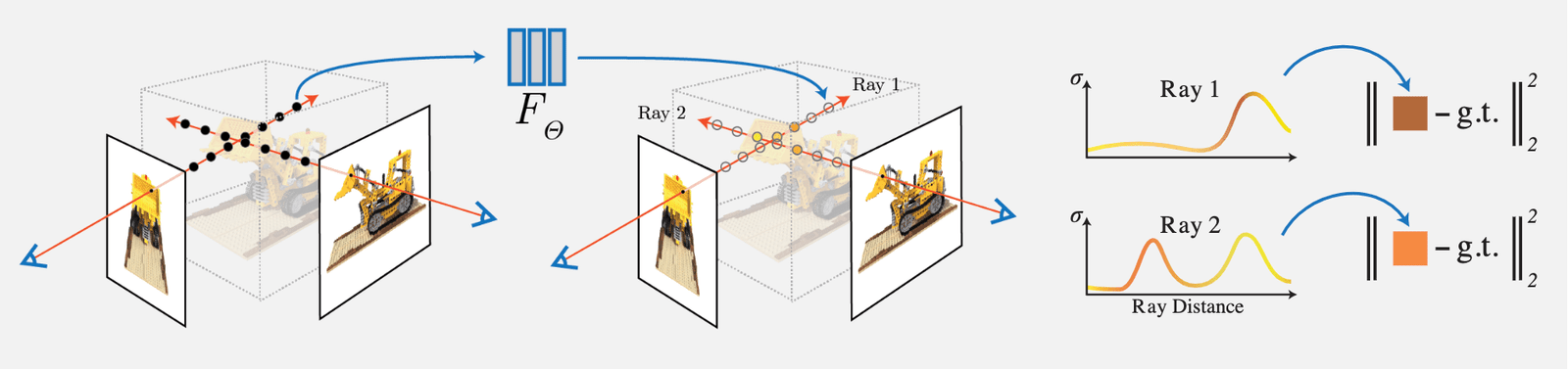
주요 작업 및 혁신점은 다음과 같습니다:
1) 복잡한 기하학과 재질의 연속적인 장면을 표현하기 위해 5D 신경 방사장(Neural Radiance Field)을 사용하는 방법을 제안하였으며, 이 방사장은 MLP 네트워크를 사용하여 매개변수화됩니다.
2) 클래식 복셀 렌더링(Volume Rendering)을 기반으로 한 미분 가능한 렌더링 방법을 제안하여, 미분 가능한 렌더링을 통해 RGB 이미지를 얻고 이를 최적화 목표로 삼습니다. 이 부분은 계층적 샘플링 가속 전략을 포함하여, MLP의 용량을 가시적인 콘텐츠 영역에 할당합니다.
3) 각 5D 좌표를 더 높은 차원의 공간으로 매핑하는 위치 인코딩(Position Encoding) 방법을 제안하여, 신경 방사장이 고주파 세부 정보를 더 잘 표현할 수 있도록 최적화할 수 있습니다.

1 Neural Radiance Field Scene Representation (신경 방사장 기반 장면 표현)
NeRF는 연속적인 장면을 5D 벡터 값 함수로 표현합니다. 여기서:
- 입력: 3D 위치 \mathbf{x}=(x, y, z) 및 2D 시점 방향 (\theta, \phi)
- 출력: 방사 색상 \mathbf{c}=(r, g, b) 및 부피 밀도(불투명도) \sigma
2D 시점 방향에 대한 직관적인 설명은 아래 그림을 참조하십시오:
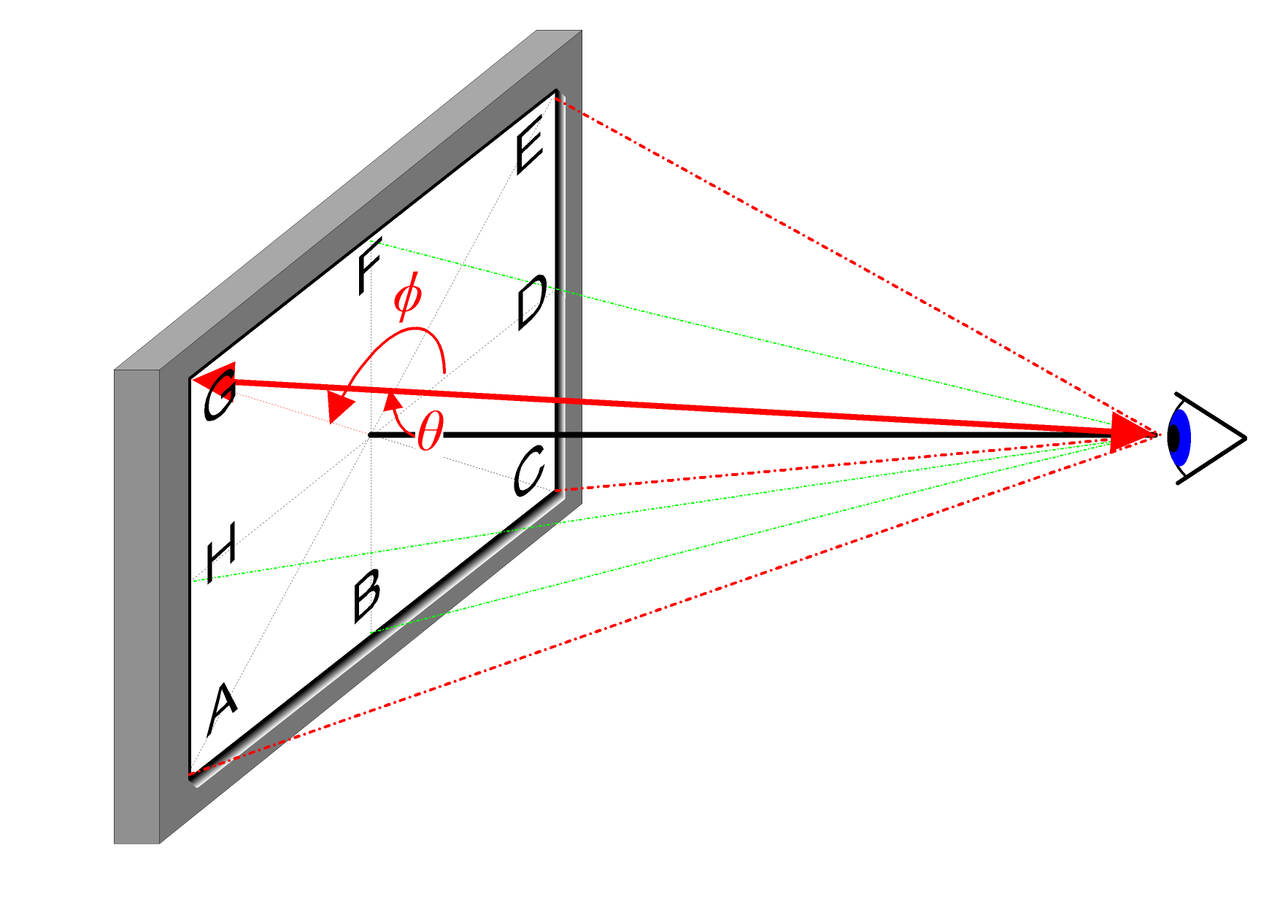
실제 구현에서 시점 방향은 3D 직교 좌표계의 단위 벡터 \mathbf{d}로 표현되며, 이는 이미지 내의 임의의 위치와 카메라 광심을 연결하는 선입니다. 우리는 MLP 완전 연결 네트워크를 사용하여 이 매핑을 표현합니다:
\begin{equation}F_{\Theta}:(\mathbf{x}, \mathbf{d}) \rightarrow(\mathbf{c}, \sigma)\end{equation}
이러한 네트워크의 매개변수 \Theta를 최적화하여, 5D 좌표 입력을 해당 색상 및 밀도 출력으로 매핑하는 방법을 학습합니다.
다중 시점 표현을 학습하기 위해, 우리는 다음 두 가지 합리적인 가정을 합니다:
- 부피 밀도(불투명도) \sigma는 3D 위치 \mathbf{x}에만 관련이 있으며, 시점 방향 \mathbf{d}와는 무관합니다. 물체의 다른 위치에서의 밀도는 관찰 각도와 무관해야 하며, 이는 명백합니다.
- 색상 \mathbf{c}는 3D 위치 \mathbf{x} 및 시점 방향 \mathbf{d} 모두와 관련이 있습니다.
부피 밀도 \sigma를 예측하는 네트워크 부분의 입력은 단순히 위치 \mathbf{x}이며, 색상 \mathbf{c}를 예측하는 네트워크 입력은 시점과 방향 \mathbf{d}입니다. 구체적인 구현에서는:
- MLP 네트워크 F_{\Theta}는 먼저 8개의 완전 연결 레이어(각 레이어는 ReLU 활성화 함수를 사용하며, 각 레이어는 256개의 채널을 가집니다)를 사용하여 3D 좌표 \mathbf{x}를 처리하고, \sigma와 256차원의 특성 벡터를 얻습니다.
- 이 256차원의 특성 벡터를 시점 방향 \mathbf{d}와 결합하여 또 다른 완전 연결 레이어(각 레이어는 ReLU 활성화 함수를 사용하며, 각 레이어는 128개의 채널을 가집니다)에 입력하고, 방향 관련 RGB 색상을 출력합니다.
아래는 본문에서 제시된 네트워크 구조의 예시입니다:


Fig 3은 우리의 네트워크가 비람버트 효과(non-Lambertian effects)를 표현할 수 있음을 보여줍니다. Fig 4는 훈련 시 시점(View Dependence)의 입력이 없을 경우(\mathbf{x}만 있을 경우), 네트워크가 하이라이트 효과를 표현할 수 없음을 보여줍니다.

2 Volume Rendering with Radiance Fields (방사장 기반 복셀 렌더링)
2.1 고전적인 렌더링 방정식
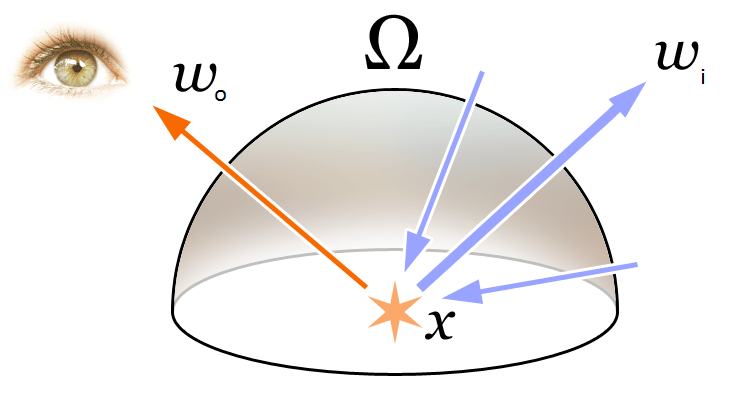
Radiance Field와 Volume Rendering의 개념을 이해하기 위해, 먼저 그래픽스에서 가장 기본적인 렌더링 방정식을 다시 살펴보겠습니다:
\begin{equation}\begin{array}{l}L_{o}(\boldsymbol{x}, \boldsymbol{d}) &=L_{e}(\boldsymbol{x}, \boldsymbol{d})+\int_{\Omega} f_{r}\left(\boldsymbol{x}, \boldsymbol{d}, \boldsymbol{\omega}_{i}\right) L_{i}\left(\boldsymbol{x}, \boldsymbol{\omega}_{i}\right) \left(\boldsymbol{\omega}_{i}, \boldsymbol{n}\right) d \boldsymbol{\omega}_{i}\\&=L_{e}(\boldsymbol{x}, \boldsymbol{d})+\int_{\Omega} f_{r}\left(\boldsymbol{x}, \boldsymbol{d}, \boldsymbol{\omega}_{i}\right) L_{i}\left(\boldsymbol{x}, \boldsymbol{\omega}_{i}\right) \cos \theta d \boldsymbol{\omega}_{i}\end{array}\end{equation}
위 그림에서 보듯이, 렌더링 방정식은 3D 공간 위치 \mathbf{x}에서 방향 \mathbf{d}로의 방사(출사광) L_{o}(\boldsymbol{x}, \boldsymbol{d})를 표현합니다. 이 방사는 해당 지점에서 외부로 방사되는 방사(발광) L_{e}(\boldsymbol{x}, \boldsymbol{d})와 해당 지점에서 외부로 반사되는 방사(반사광)의 합으로 표현됩니다. 구체적으로:
- L_{e}(\boldsymbol{x}, \boldsymbol{d})는 \mathbf{x}가 광원일 때 방향 \mathbf{d}로 방출되는 방사(발광)를 나타냅니다.
- \int_{\Omega} f_{r}\left(\boldsymbol{x}, \boldsymbol{d}, \boldsymbol{\omega}_{i}\right) L_{i}\left(\boldsymbol{x}, \boldsymbol{\omega}_{i}\right) \cos \theta d \boldsymbol{\omega}_{i}는 입사 방향 반구의 적분을 나타냅니다.
- f_{r}\left(\boldsymbol{x}, \boldsymbol{d}, \boldsymbol{\omega}_{i}\right)는 산란 함수로, 입사 방향에서 출사 방향으로의 방사 비율을 나타냅니다.
- L_{i}\left(\boldsymbol{x}, \boldsymbol{\omega}_{i}\right)는 \boldsymbol{\omega}_{i} 방향에서 수신된 방사를 나타냅니다.
- \boldsymbol{n}은 3D 공간 위치 \mathbf{x}의 법선이며, \theta는 \boldsymbol{\omega}_{i}와 \boldsymbol{n} 사이의 각도입니다. 따라서 \left(\boldsymbol{\omega}_{i}, \boldsymbol{n}\right)=\cos \theta입니다.
방사 개념을 간단히 이해하면, 물리학에서 빛은 전자기 방사입니다. 우리는 전자파의 파장 \lambda와 주파수 \nu 사이의 관계식을 알고 있습니다:
\begin{equation}c=\lambda \nu\end{equation}
즉, 둘의 곱은 빛의 속도 c입니다. 그리고 우리는 가시광선의 색상 RGB가 서로 다른 주파수의 빛 방사가 카메라에 작용한 결과라는 것을 알고 있습니다. 따라서 NeRF에서는 방사장을 색상의 근사 모델로 간주합니다.
2.2 고전적인 복셀 렌더링 방법
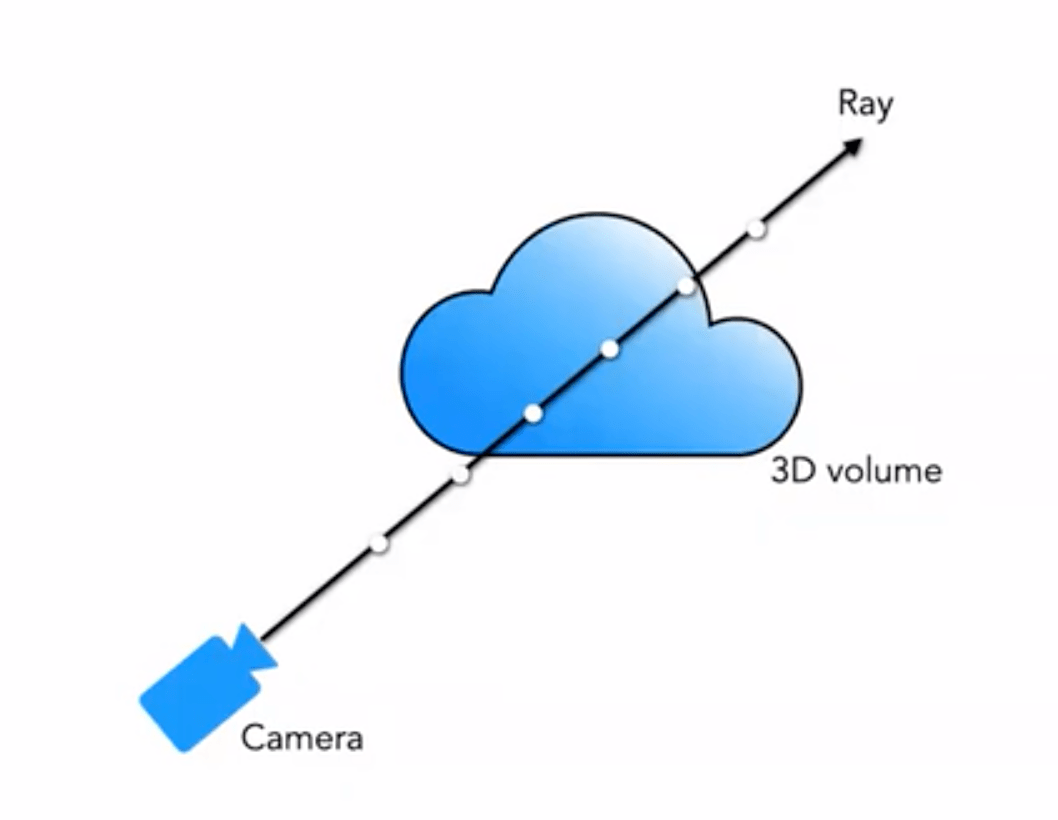
우리가 일반적으로 접하는 것은 메쉬 렌더링, 복셀 렌더링 등입니다. 구름, 연기 등의 특수 효과에는 주로 복셀 렌더링이 사용됩니다:

우리의 5D 신경 방사장은 장면을 그 공간 내 임의의 지점에서의 복셀 밀도와 방향성 방사 밝기로 표현합니다. 복셀 밀도 \sigma(\mathbf{x})는 광선이 위치 \mathbf{x}에 머무는 무한소 입자의 확률로 정의됩니다(또는 광선이 이 지점을 통과한 후 종료할 확률로 이해할 수 있습니다). 고전적인 입체 렌더링 원리를 사용하여, 우리는 장면을 통과하는 임의의 광선의 색상을 렌더링할 수 있습니다.
따라서 시점 \mathbf{o}에서 발사된 방향 \mathbf{d}의 광선이 t 시점에 도달하는 지점은 다음과 같습니다:
\begin{equation}\mathbf{r}(t)=\mathbf{o}+t \mathbf{d}\end{equation}
\sin \left(2^{L-1} \pi p\right), \cos \left(2^{L-1} \pi p\right)\right)
\end{equation}
[/latex]
이 함수 \gamma(\cdot) 는 3차원 위치 좌표 \mathbf{x} (정규화된 [-1, 1])와 3차원 시점 방향의 데카르트 좌표 \mathbf{d} 에 적용됩니다. 본문에서는 \gamma(\mathbf{x}) 에 대해 L=10으로 설정하고, \gamma(\mathbf{d}) 에 대해 L=4로 설정합니다.
따라서 3차원 위치 좌표의 인코딩 길이는 다음과 같습니다: 3 \times 2 \times 10 = 60, 3차원 시점 방향의 위치 인코딩은 3 \times 2 \times 4 = 24로, 네트워크 구조도 상의 입력 차원과 일치합니다.
유사하게, Transformer에서도 비슷한 위치 인코딩 작업이 있지만, 본문에서는 근본적으로 다릅니다. Transformer에서는 위치 인코딩이 입력 시퀀스 정보를 나타내기 위한 것이지만, 여기서는 위치 인코딩이 입력을 고차원으로 매핑하여 네트워크가 고주파 정보를 더 잘 학습할 수 있도록 하는 데 사용됩니다.
3.2 Hierarchical Sampling Procedure (계층적 샘플링 절차)
계층적 샘플링 절차는 고전적인 렌더링 알고리즘의 가속 작업에서 비롯되었습니다. 앞서 언급한 볼륨 렌더링(Volume Rendering) 방법에서, 광선상의 점을 어떻게 샘플링하느냐가 최종 효율성에 영향을 미칩니다. 샘플링 점이 너무 많으면 계산 효율이 떨어지고, 너무 적으면 정확한 근사값을 얻지 못합니다. 따라서 자연스럽게 색상 기여도가 큰 점 근처에서는 샘플링을 촘촘하게 하고, 기여도가 작은 점 근처에서는 샘플링을 드물게 하는 것이 문제를 해결하는 방법입니다. 이러한 아이디어를 바탕으로 NeRF는 자연스럽게 거칠게 시작하여 세밀하게 진행하는 계층적 샘플링 절차(Coarse to Fine)를 제안했습니다.
Coarse 부분: 먼저 거친 네트워크에 대해, 우리는 N_c 개의 희소 점(c는 Coarse를 의미)을 샘플링하고, 식 (3)을 새로운 형태로 수정합니다(가중치 추가):
\begin{equation}\hat{C}_{c}(\mathbf{r})=\sum_{i=1}^{N_{c}} w_{i} c_{i}, \quad w_{i}=T_{i}\left(1-\exp \left(-\sigma_{i} \delta_{i}\right)\right)\end{equation}
여기서 가중치는 정규화되어야 합니다:
\begin{equation}\hat{w}_{i}=\frac{w_{i}}{\sum_{j=1}^{N_{c}} w_{j}}\end{equation}
이 가중치 \hat{w}_{i} 는 광선을 따라 분절된 상수 확률 밀도 함수(Piecewise-constant PDF)로 볼 수 있습니다. 이 확률 밀도 함수를 통해 광선상의 물체 분포를 대략적으로 얻을 수 있습니다.
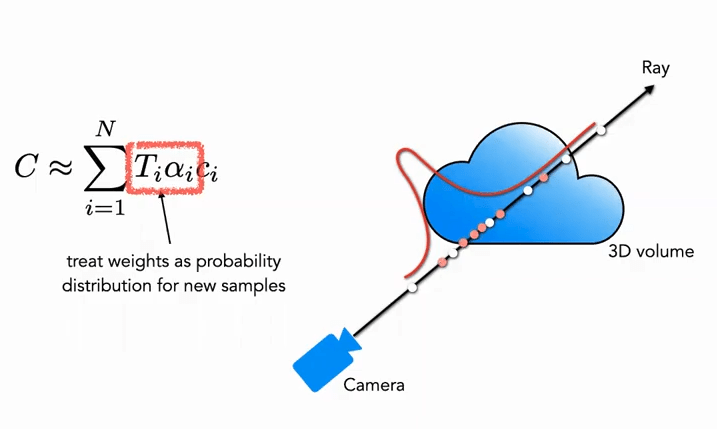
Fine 부분: 두 번째 단계에서는 역변환 샘플링(Inverse Transform Sampling)을 사용하여 위에서 얻은 분포에 따라 두 번째 집합 N_f을 샘플링하고, 최종적으로 여전히 식 (3)을 사용하여 \hat{C}_{f}(\mathbf{r})을 계산합니다. 하지만 이번에는 전체 N_c + N_f 샘플을 사용합니다. 이 방법을 사용하면 두 번째 샘플링은 실제로 장면 내용이 있는 영역에서 더 많은 샘플을 분포에 따라 샘플링할 수 있으며, 이는 중요도 샘플링(Importance Sampling)을 실현합니다.
그림에서 볼 수 있듯이, 흰색 점은 첫 번째 균일 샘플링의 점을 나타내며, 흰색 균일 샘플링 후 얻은 분포에 따라 두 번째로 빨간 점을 샘플링합니다. 확률이 높은 곳에서는 촘촘하게, 확률이 낮은 곳에서는 드물게 샘플링됩니다(입자 필터와 유사).
3.3 Implementation Details (구현 세부 사항)
훈련 손실 함수 측면에서, 본문의 정의는 매우 간단하고 직관적입니다. 거친 네트워크와 정밀 네트워크 모두에 대해 렌더링된 L_2 손실을 사용하며, 공식은 다음과 같습니다:
\begin{equation}\mathcal{L}=\sum_{\mathbf{r} \in \mathcal{R}}\left[\left\|\hat{C}_{c}(\mathbf{r})-C(\mathbf{r})\right\|_{2}^{2}+\left\|\hat{C}_{f}(\mathbf{r})-C(\mathbf{r})\right\|_{2}^{2}\right]\end{equation}
여기서:
- \mathcal{R} 은 배치 내의 모든 샘플링된 광선 집합을 나타냅니다
- C(\mathbf{r}) 은 실제 RGB 색상을 나타냅니다
- \hat{C}_{c}(\mathbf{r}) 은 거친 네트워크가 예측한 RGB 색상을 나타냅니다
- \hat{C}_{f}(\mathbf{r}) 은 정밀 네트워크가 예측한 RGB 색상을 나타냅니다
4 Results (실험 결과)
본문에서는 많은 관련 작업들과 비교를 수행했습니다. 예를 들어:
- Neural Volumes (NV): https://github.com/facebookresearch/neuralvolumes
- Scene Representation Networks (SRN): https://github.com/vsitzmann/scene-representation-networks
- Local Light Field Fusion (LLFF): https://github.com/Fyusion/LLFF
4.1 Datasets (데이터셋)
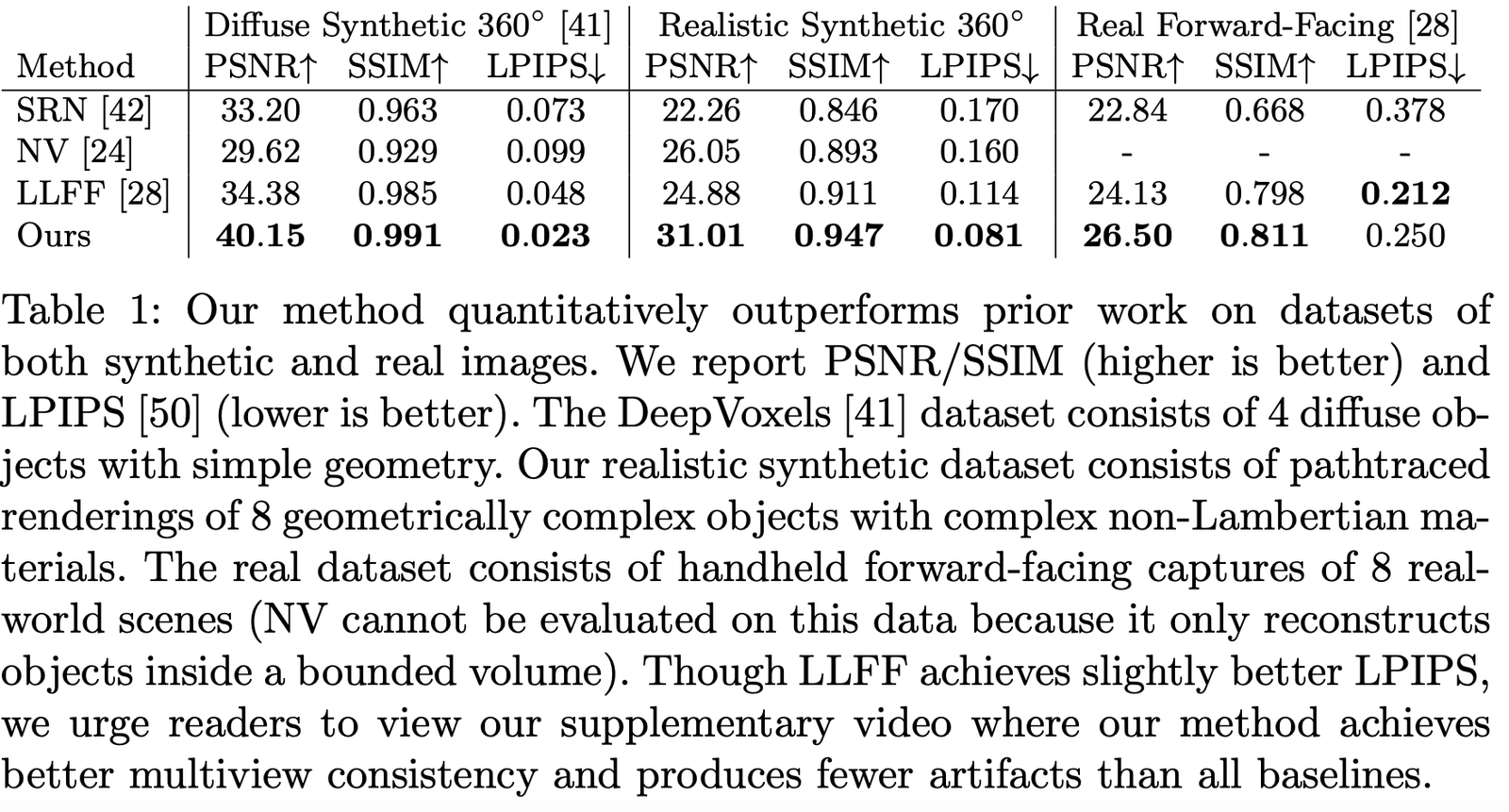
저자는 다양한 데이터셋에서의 성능을 비교했으며, 거의 모든 데이터셋에서 압도적인 성능을 보여주었습니다:
시뮬레이션 데이터셋에서의 시각화 결과:

실제 데이터셋에서의 시각화 결과:

4.2 Ablation Studies (소거 실험)
우리는 Realistic Synthetic 360◦ 데이터셋에서 다양한 매개변수와 설정에 따른 소거 실험을 수행했으며, 결과는 다음과 같습니다:
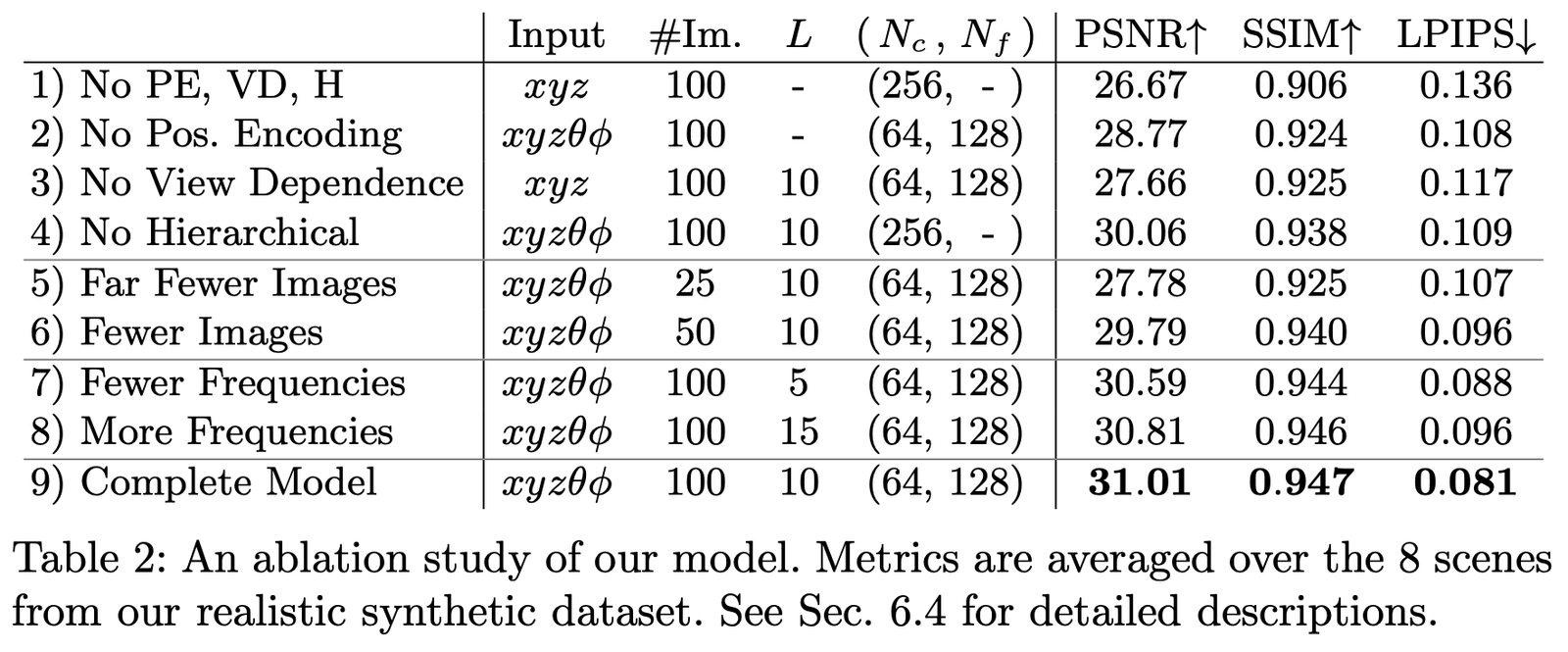
주요 비교 항목은 다음과 같습니다:
- Positional encoding (PE), 즉 \mathbf{x}
- View Dependence (VD), 즉 \mathbf{d}
- Hierarchical sampling (H)
그 중:
1행은 위의 어느 부분도 포함하지 않은 최소 네트워크를 나타냅니다.
2-4행은 각각 하나의 부분을 제거한 경우를 나타냅니다.
5-6행은 샘플 이미지가 적을 때의 성능 차이를 나타냅니다.
7-8행은 주파수 L (즉, 위치 인코딩 \mathbf{x}의 주파수 확장 수준)이 다를 때의 성능 차이를 나타냅니다.
논문 요약
이 논문의 가장 큰 혁신점은 암시적 표현을 통해 3차원 장면 표현을 인위적으로 설계하는 방법을 우회하여, 더 높은 차원에서 장면의 3차원 정보를 학습할 수 있다는 점입니다. 그러나 단점은 속도가 매우 느리다는 것입니다. 이 점은 후속 연구에서 많은 개선이 이루어졌습니다. 한편, 이 논문의 설명 가능성과 암시적 표현의 능력은 여전히 더 많은 연구가 필요합니다.
결국, 이러한 간결하고 효과적인 방법이 3D 및 4D 장면 재구성의 혁신점이 되어, 3차원 비전에 새로운 도약을 가져올 것이라고 믿습니다.
논문 다운로드
PDF | Website | Code (Official) | Code (Pytorch Lightning) | Recording | Recording (Bilibili)
Colab Example: Tiny NeRF | Full NeRF
참고 자료
[1] Mildenhall B, Srinivasan P P, Tancik M, et al. Nerf: Representing scenes as neural radiance fields for view synthesis[C]//European Conference on Computer Vision. Springer, Cham, 2020: 405-421.
[2] https://www.cnblogs.com/noluye/p/14547115.html
[3] https://www.cnblogs.com/noluye/p/14718570.html
[4] https://github.com/yenchenlin/awesome-NeRF
[5] https://zhuanlan.zhihu.com/p/360365941
[6] https://zhuanlan.zhihu.com/p/380015071
[7] https://blog.csdn.net/ftimes/article/details/105890744
[8] https://zhuanlan.zhihu.com/p/384946242
[9] https://zhuanlan.zhihu.com/p/386127288
[10] https://blog.csdn.net/g11d111/article/details/118959540
[11] https://www.bilibili.com/video/BV1fL4y1T7Ag
[12] https://zh.wikipedia.org/wiki/%E6%B8%B2%E6%9F%93%E6%96%B9%E7%A8%8B
[13] https://zhuanlan.zhihu.com/p/380015071
[14] https://blog.csdn.net/soaring_casia/article/details/117664146
[15] https://www.youtube.com/watch?v=Al6NTbgka1o
[16] https://github.com/matajoh/fourier_feature_nets
관련 작업
DSNeRF: https://github.com/dunbar12138/DSNeRF (SfM 가속 NerF)
BARF: https://github.com/chenhsuanlin/bundle-adjusting-NeRF
PlenOctrees: https://alexyu.net/plenoctrees/ (PlenOctrees를 사용한 NeRF 렌더링 가속)
https://github.com/google-research/google-research/tree/master/jaxnerf (JAX를 사용한 훈련 속도 향상)