CVPR 2021 이미지 매칭 챌린지 이중 우승 알고리즘 회고
이전에 회사에 제공한 글을 참고하여, 최근 대회에서의 실험과 생각을 요약합니다. 본문 저작권: 메그비 테크놀로지. 원문 링크: https://www.zhihu.com/question/32066833/answer/2041516754
Image Matching(이미지 매칭)은 컴퓨터 비전 분야에서 가장 기본적인 기술 중 하나로, 이는 희소 또는 밀집 특징 매칭 방식을 통해 두 이미지의 동일한 위치에 있는 국부 정보를 연결하는 것을 의미합니다. Image Matching은 로봇, 자율주행차, AR/VR, 이미지/상품 검색, 지문 인식 등 다양한 분야에서 널리 사용됩니다.
올해 막 끝난 CVPR 2021 Image Matching 대회에서 메그비 3D 팀은 두 개의 우승과 하나의 준우승을 차지했습니다. 이 글에서는 그들의 대회 전략, 실험 및 몇 가지 생각을 소개합니다.



대회 소개
이미지 매칭이란 두 이미지에서 동일하거나 유사한 속성의 내용 또는 구조를 픽셀 단위로 인식하고 정렬하는 것을 말합니다. 일반적으로 매칭할 이미지는 동일하거나 유사한 장면 또는 목표에서 가져오거나, 동일한 형태 또는 의미 정보를 가진 다른 유형의 이미지 쌍으로, 어느 정도의 매칭 가능성을 가집니다.
Image Matching Challenge

이번 Image Matching Challenge(IMC) 대회는 두 개의 트랙으로 나뉩니다. 하나는 unlimited keypoints, 다른 하나는 restricted keypoints로, 각 이미지에서 추출할 수 있는 특징점의 수가 각각 8k와 2k 이하입니다.
올해 IMC 대회에는 세 개의 데이터셋이 사용되었으며, 각각 Phototourism, PragueParks, GoogleUrban입니다. 이 세 데이터셋은 차이가 크며, 알고리즘의 일반화 능력이 상당히 요구됩니다. 주최 측은 세 데이터셋 모두에서 좋은 성능을 발휘할 수 있는 방법을 찾고자 했으며, 최종 순위는 이 세 데이터셋의 순위 평균으로 결정됩니다.
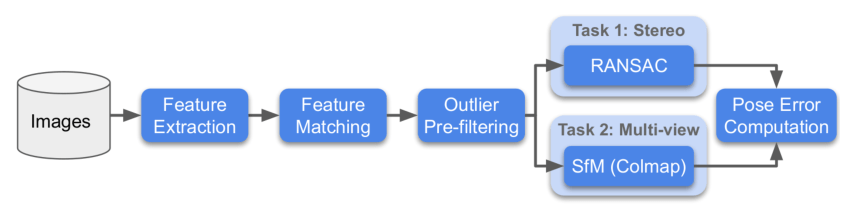
각 데이터셋에 대해 주최 측은 Stereo와 Multiview라는 두 가지 방법으로 평가를 진행하며, 각각의 작업에 대해 순위를 매깁니다.
- Stereo: 두 이미지 간의 매칭을 통해 F 매트릭스를 계산하고 실제 위치 오차를 구합니다.
- Multiview: 일부 이미지를 선택하여 bags를 구성하고, bags를 통해 맵핑을 수행하며, 3D 모델을 통해 서로 다른 이미지 간의 위치 오차를 계산합니다.
아래는 대회 프로세스 흐름도입니다:
SimLoc Match

SimLoc은 다양한 장면을 포함하는 데이터셋으로, IMC 데이터셋과 다른 점은 합성 데이터셋이라는 점이며, 완전히 정확한 ground truth를 얻을 수 있습니다.
대회에는 세 가지 지표가 있으며, 최종적으로 매칭 성공률을 최종 순위 평가 지표로 사용합니다. 세 가지 지표는 다음과 같습니다:
- 내점 수(높을수록 좋음)
- 매칭 성공률, 즉 매칭된 내점 수/제공된 모든 매칭 쌍(높을수록 좋음)
- 부정 매칭 쌍 수, 두 이미지에 공통 시야 영역이 없을 때, 매칭 쌍은 적을수록 좋음
전략
데이터 분석


우선 대회의 세 가지 데이터셋을 분석합니다.
- 검증 세트와 테스트 세트 간에 갭이 존재하는지 관찰합니다.
- 각 데이터셋의 너비와 높이를 통계적으로 분석하여 리사이즈 크기를 결정합니다.
파이프라인
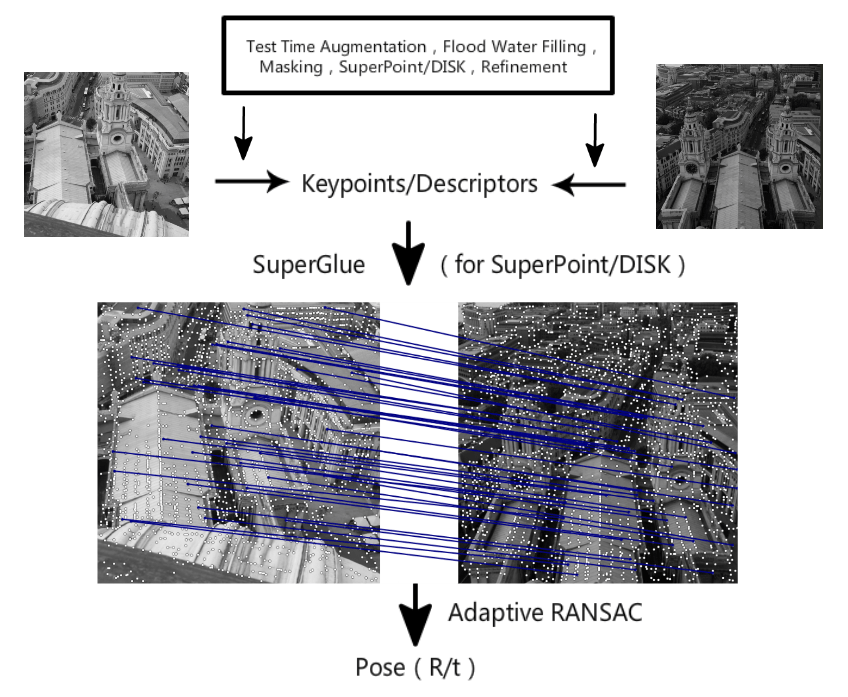
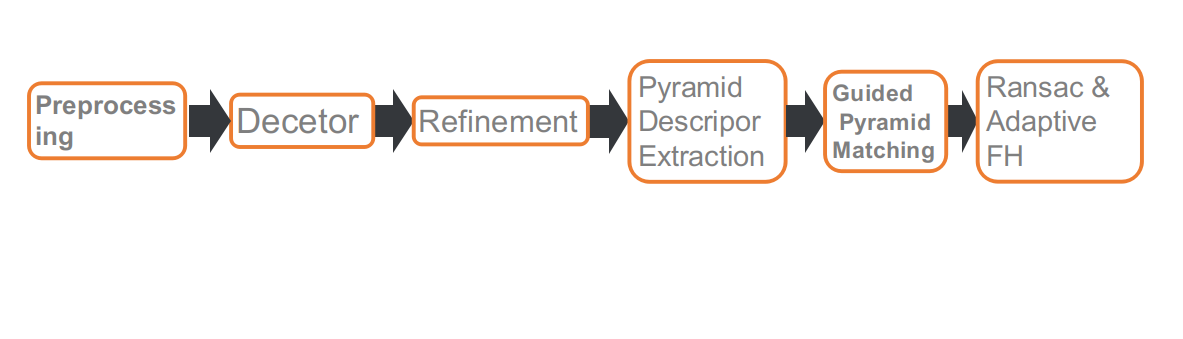
이것이 우리의 대회 파이프라인입니다. 총 여섯 부분으로 구성되어 있습니다. 각각은: 전처리, 특징점 검출, 특징점 위치 정제, 다중 스케일 또는 다중 각도에서의 디스크립터 추출, Guided 매칭, 그리고 적응형 FH 기반의 RANSAC입니다.
전처리


IMC 트랙에서는 특징점 수에 제한이 있기 때문에, 특징점의 위치가 매우 중요합니다. 예를 들어, 보행자, 차량, 하늘과 같은 동적 물체는 매칭을 통해 위치를 계산하는 데 도움이 되지 않거나 오히려 부정적인 영향을 미칩니다. 그래서 우리는 세그멘테이션 네트워크를 사용하여 이러한 물체를 마스크 처리하고, 특징점을 추출할 때 마스크 영역을 건너뛰도록 했습니다.
세그멘테이션 네트워크를 사용한 전처리 후, 두 가지 문제를 발견했습니다.
- 첫 번째는 세그멘테이션 네트워크의 정확도가 높지 않아 건물과 하늘의 경계 영역을 잘 구분하지 못해 건물의 가장자리가 손상되는 경우가 있었습니다. 이는 매칭에 불리합니다. 그래서 동적 물체를 마스크 처리한 후, 마스크 영역에 침식 처리를 하여 건물의 가장자리 세부 사항을 보존했습니다.
- 두 번째 문제는 세그멘테이션 네트워크 알고리즘이 사람과 조각상을 구분하는 능력이 좋지 않다는 것입니다. 보행자를 마스크 처리할 때 조각상도 함께 마스크 처리되는 경우가 있었습니다. 일부 장면, 예를 들어 링컨 데이터셋에서는 조각상의 특징점이 매칭 결과에 매우 중요합니다. 이 문제를 해결하기 위해 우리는 조각상과 보행자를 구분하는 분류 네트워크를 훈련하여, 보행자는 제거하고 조각상은 보존할 수 있도록 했습니다.
전처리 작업을 통해, Phototourism 검증 세트의 Stereo와 Multiview 작업에서 각각 1.1%와 0.3%의 성능 향상을 달성했습니다.
특징점 추출
Adapt Homographic
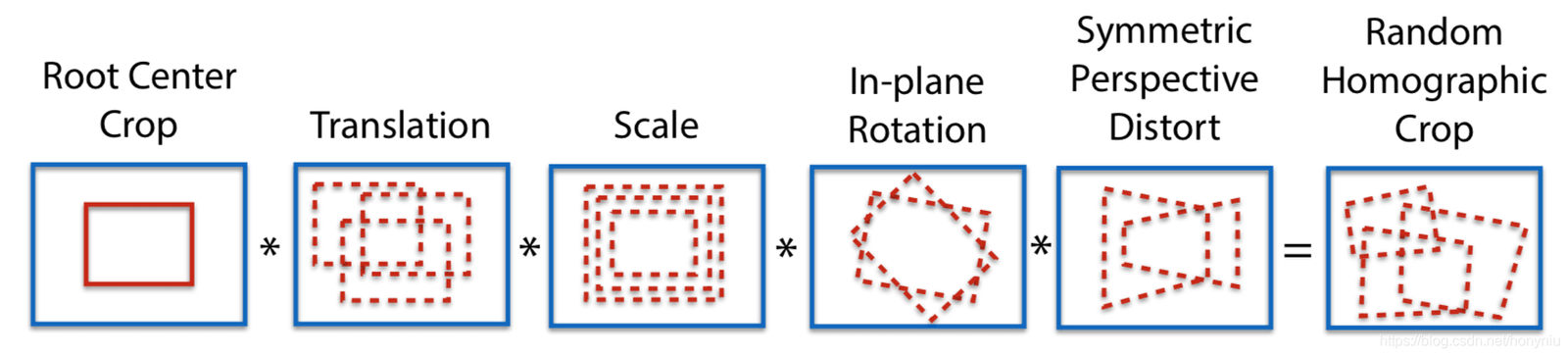
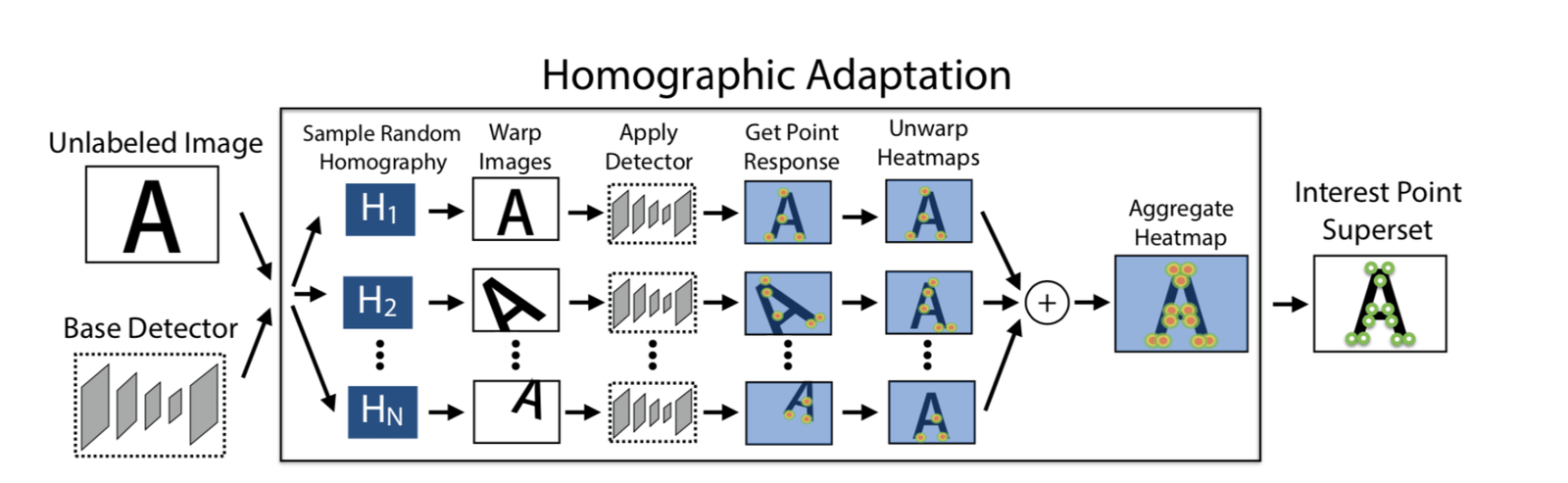
100번의 호모그래피 변환을 사용하여 100장의 변환된 이미지를 얻고, 이러한 이미지에서 SuperPoint 모델을 사용하여 각각 특징점을 추출합니다. 이를 통해 n개의 특징점 히트맵을 얻을 수 있으며, 이 n개의 히트맵을 합쳐 최종 히트맵을 얻습니다. 그런 다음 필요한 만큼 특징점을 선택합니다. 이렇게 하면 더 많은 특징점을 추출할 수 있을 뿐만 아니라, 특징점의 위치도 더 합리적으로 배치됩니다.
Adapt Homographic을 사용하여 Phototourism 검증 세트의 Stereo와 Multiview 작업에서 각각 1.7%와 1.3%의 성능 향상을 달성했습니다.
Refinement
SuperPoint에서 추출된 특징점은 정수입니다. 우리는 soft argmax refinement를 사용하여 반지름 2의 파라미터로 서브픽셀화하여, 특징점 위치를 더 정확하게 만듭니다. Refinement 방법을 사용하여 Phototourism 검증 세트의 Stereo와 Multiview 작업에서 각각 0.8%와 0.35%의 성능 향상을 달성했습니다.
NMS

DISK 특징 추출 방법으로 추출된 특징점들을 관찰한 결과, 특징점이 밀집된 경우가 많았습니다. 이로 인해 일부 영역에 특징점이 없는 문제가 발생했습니다.
이 문제를 완화하기 위해, 우리는 더 큰 반지름의 NMS를 사용했습니다. NMS 반지름을 3에서 10으로 확장하여, 특징점 밀집 현상이 개선되었습니다. PragueParks 검증 세트의 Stereo 작업에서 0.57%의 성능 향상을 달성했습니다.
피라미드 디스크립터 && Guided 피라미드 매칭
코너 케이스 분석


베이스라인을 구축한 후, 우리는 테스트 세트에서 무작위로 샘플링하여 일부 이미지를 선택하고 코너 케이스를 분석했습니다. 관찰 결과, 매칭 성능이 좋지 않은 주된 이유는 두 가지 경우 때문이었습니다. 또는 두 가지 경우가 동시에 발생했습니다.
- 스케일 차이가 큼
- 큰 각도 회전
위의 코너 케이스에 대해, 우리는 피라미드 디스크립터 추출 및 Guided 매칭 전략을 채택했습니다.

동일한 특징점 세트를 기반으로 다양한 스케일과 각도에서 디스크립터를 추출합니다. 즉, 특징점은 한 이미지에서 추출되며, 디스크립터는 특징점의 매핑을 통해 다른 이미지에서 추출됩니다.
매칭 시, 먼저 임계값 t를 설정하고, 매칭 수가 임계값 t보다 크면 원래 스케일 또는 원래 각도로 매칭을 수행합니다. 매칭 수가 임계값 t보다 작으면 다중 스케일 매칭 또는 다중 각도 매칭을 사용합니다.
이러한 수정 후, 위의 코너 케이스에서 매칭 성능이 개선되었습니다.


위의 전략을 통해 세 데이터셋 검증 세트의 Stereo와 Multiview 작업에서 평균 0.4%의 성능 향상을 달성했습니다.
SuperGlue 재훈련
또한 우리는 SuperGlue를 다시 훈련했습니다. 여기에는 두 가지 측면이 있습니다. 하나는 공식 SuperPoint+SuperGlue 방법을 재현하는 것이고, 다른 하나는 더 나은 특징 추출 방법인 DISK를 사용하여 DISK+SuperGlue를 훈련하는 것입니다. DISK+SuperGlue는 YFCC 검증 세트에서 공식 SuperPoint+SuperGlue보다 약 4% 높은 성능을 보였습니다.
대회 데이터셋에 대해 DISK+SuperGlue는 Phototourism에서 좋은 성능을 보였지만, 다른 두 데이터셋에서는 성능이 떨어졌습니다. 이는 DISK가 Megadepth에서 훈련되어 건물 데이터셋에 과적합되었기 때문일 수 있습니다. 반면, SuperPoint는 COCO에서 훈련되었으며, COCO는 더 다양한 장면을 포함하고 있어 일반화 능력이 더 뛰어납니다.
마지막으로 8k 트랙(unlimited keypoints)에서 우리는 SuperPoint+SuperGlue와 DISK+SuperGlue를 앙상블하여, 두 방법을 단독으로 사용할 때보다 더 나은 성능을 얻었습니다.
| Methods | Phototourism | PragueParks | GoogleUrban | |||
|---|---|---|---|---|---|---|
| Stereo | Multiview | Stereo | Multiview | Stereo | Multiview | |
| SP-SG(4K) | 0.60357 | 0.78290 | 0.79766 | 0.50499 | 0.41212 | 0.32472 |
| DISK-SG(8K) | 0.61955 ↑ | 0.77531 | 0.72002 | 0.48548 | 0.38764 | 0.26281 |
| SP-DISK-SG | 0.63975 ↑ | 0.78564 ↑ | 0.80700 ↑ | 0.49878 | 0.43952 ↑ | 0.33734 ↑ |
RANSAC && Adapt FH
우리는 먼저 여러 RANSAC 방법을 시도했습니다. 예를 들어 OpenCV의 기본 RANSAC 방법, DEGENSAC 방법, MAGSAC++ 방법 등을 사용해 보았으며, 실험 결과 DEGENSAC가 가장 좋은 성능을 보였습니다.
또한 DEGENSAC는 F 매트릭스를 사용하여 계산할 때 평면 퇴화 문제가 발생할 수 있습니다. 예를 들어 다음과 같은 경우입니다.

평면 퇴화 문제를 해결하기 위해, 우리는 ORB-SLAM에서 영감을 받아 적응형 FH 전략을 설계했습니다. 구체적인 알고리즘은 다음과 같습니다:

응용: AR 내비게이션
메그비는 최첨단 알고리즘과 실제 비즈니스를 결합하는 것을 매우 중요하게 생각하며, 본문에서 소개한 Image Matching 기술은 S800V SLAM 로봇, AR 내비게이션 등 여러 프로젝트에 이미 적용되었습니다.
메그비의 한 "실내 비전 위치 내비게이션" 프로젝트를 예로 들면, 대규모 SfM 희소 포인트 클라우드 재구성 기술과 Image Matching 등의 기술을 활용하여, 메그비 3D 팀은 스마트폰 카메라만으로 복잡한 실내 환경에서 정확한 위치 파악과 AR 내비게이션 기능을 구현했습니다. 기존의 GPS, 블루투스 등 실내 위치 추적 솔루션에 비해, "실내 비전 위치 내비게이션"은 센티미터급 맵핑 정확도, 미터 이하의 위치 정확도를 제공하며, 실내 환경에 추가적인 장치를 설치할 필요가 없어 고객의 "고정밀, 쉬운 배포 및 유지 관리" 요구를 충족시킵니다. 현재 여러 대형 실내 환경의 위치 내비게이션 프로젝트에 성공적으로 입찰되었습니다.
이 기술을 더 직관적으로 경험할 수 있도록, 실내 비전 위치 내비게이션 앱 "MegGo"가 메그비 내부에서 출시되었으며, 각 작업 구역의 실내 위치 추적 및 내비게이션을 지원합니다. 낯선 작업 구역에 있더라도 이 전자 "가이드"를 사용하여 회의실 등 목적지로 빠르고 정확하게 안내받을 수 있습니다. 메그비를 방문하는 사람들도 스마트폰에 MegGo를 다운로드하여 작업 구역 내 위치 추적 및 내비게이션을 경험할 수 있습니다(아래 그림은 MegGo를 사용한 비전 위치 추적 및 AR 내비게이션을 각각 보여줍니다).
[gif-player id="3304"]
비전 위치 추적
[gif-player id="3305"]
AR 내비게이션
미래 전망
- 훈련 시 강화 학습을 추가하여 전체 파이프라인을 다시 훈련할 수 있습니다.
- DISK의 일반화 능력을 강화하고, 더 많은 데이터셋을 사용하여 훈련할 수 있습니다.
- Refinements 네트워크를 사용하여 특징점 위치를 정제할 수 있습니다.
참고 문헌
1. D. DeTone, T. Malisiewicz, and A. Rabinovich, “SuperPoint: Self-supervised interest point detection and description,”CoRR, vol. abs/1712.07629, 2017.
2. M. Tyszkiewicz, P. Fua, and E. Trulls, “DISK: Learning local features with policy gradient,” Advances in Neural Informa-tion Processing Systems, vol. 33, 2020.
3. K. He, G. Gkioxari, P. Dollár, and R. B. Girshick,“Mask R-CNN,” CoRR, vol. abs/1703.06870, 2017.
4. H. Zhao, J. Shi, X. Qi, X. Wang, and J. Jia, “Pyramid scene parsing network,” in CVPR, 2017.
5. P.-E. Sarlin, D. DeTone, T. Malisiewicz, and A. Rabinovich, “SuperGlue: Learning feature matching with graph neural networks,” in CVPR, 2020.
6. D. Mishkin, J. Matas, and M. Perdoch, “Mods: Fast and robust method for two-view matching,” Computer Vision and Image Understanding, 2015.
7. C. Campos, R. Elvira, J. J. Gomez, J. M. M. Montiel, 그리고 J. D.Tardós, “ORB-SLAM3: 시각, 시각-관성 및 다중 맵 SLAM을 위한 정확한 오픈 소스 라이브러리,” arXiv 사전 인쇄 arXiv:2007.11898, 2020.