CVPR 2021 画像マッチングチャレンジ 二冠アルゴリズムの振り返り
以前に私たちが会社に提供した記事を借りて、最近のコンテストにおけるいくつかの実験と考察をまとめます。本文の著作権は:旷视科技に帰属します。元のリンク:https://www.zhihu.com/question/32066833/answer/2041516754
Image Matching(画像マッチング)はコンピュータビジョン分野における最も基本的な技術の一つであり、疎または密な特徴マッチングの方法を通じて、2枚の画像の同じ位置の局所情報を関連付けることを指します。Image Matchingは、ロボット、無人車、AR/VR、画像/商品検索、指紋認証など、多くの分野で広く応用されています。
今年終了したばかりのCVPR 2021 Image Matchingコンテストでは、旷视3Dチームが2つの優勝と1つの準優勝を獲得しました。この記事では、彼らのコンテストの戦略、実験、そしていくつかの考察を紹介します。



コンテスト紹介
画像マッチングとは、2枚の画像の同じまたは似た属性を持つ内容や構造をピクセルレベルで認識し、整列させることを指します。一般的に、マッチング対象の画像は、同じまたは似たシーンや対象から取得されたもの、または同じ形状やセマンティック情報を持つ他のタイプの画像ペアであり、一定のマッチング可能性を持っています。
Image Matching Challenge

今回のImage Matching Challenge(IMC)コンテストは、unlimited keypointsとrestricted keypointsの2つのトラックに分かれており、それぞれの画像で抽出できる特徴点の数が8k未満と2k未満です。
今年のIMCコンテストには、Phototourism、PragueParks、GoogleUrbanの3つのデータセットがあり、これらのデータセットは大きく異なり、アルゴリズムの汎化能力が求められます。主催者は、3つのデータセットすべてで良好なパフォーマンスを発揮する方法を見つけることを望んでおり、最終的な順位はこれら3つのデータセットの順位の平均で決まります。
各データセットに対して、主催者はStereoとMultiviewの2つの方法で評価を行い、それぞれのタスクのランクを求めます。
- Stereo:2枚の画像をマッチングし、F行列を解いて実際の姿勢誤差を求めます。
- Multiview:少数の画像を選んでbagsを構成し、bagsを通じてマップを作成し、3Dモデルを使って異なる画像間の姿勢誤差を求めます。
以下はコンテストのフローチャートです:
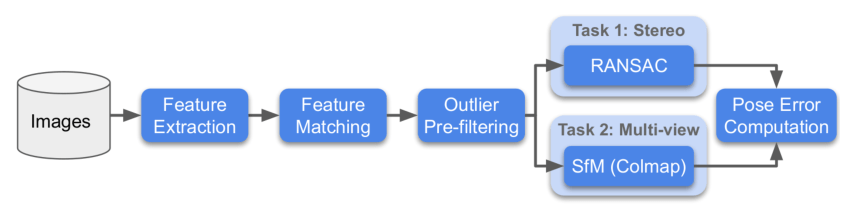
SimLoc Match

SimLocも異なるシーンを含むデータセットであり、IMCデータセットとは異なり、合成データセットであり、完全に正確なground truthを得ることができます。
コンテストには3つの指標があり、最終的にはマッチング成功率が最終的な順位評価指標として使用されます。3つの指標は次の通りです:
- インライア数(多いほど良い)
- マッチング成功率、すなわちマッチングしたインライア数/提供されたすべてのマッチングペア(高いほど良い)
- 負のマッチングペア数、2枚の画像に共視領域がない場合、マッチングペアは少ないほど良い
戦略
データ分析


まず、コンテストの3つのデータセットを分析します。
- 検証セットとテストセットの間にギャップがあるかどうかを観察する
- 各データセットの長さと幅を統計的に調べ、リサイズのサイズを決定する
パイプライン
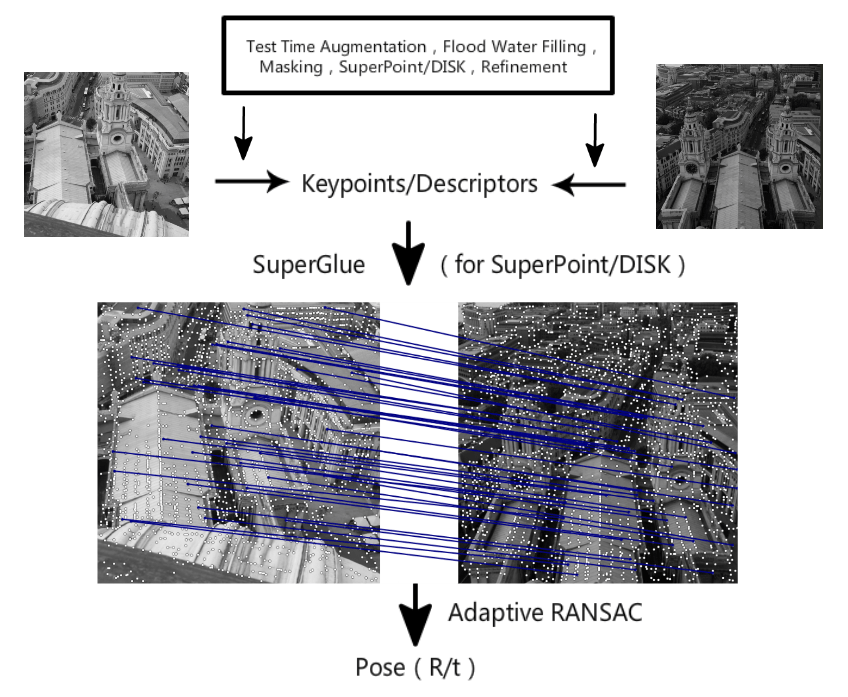
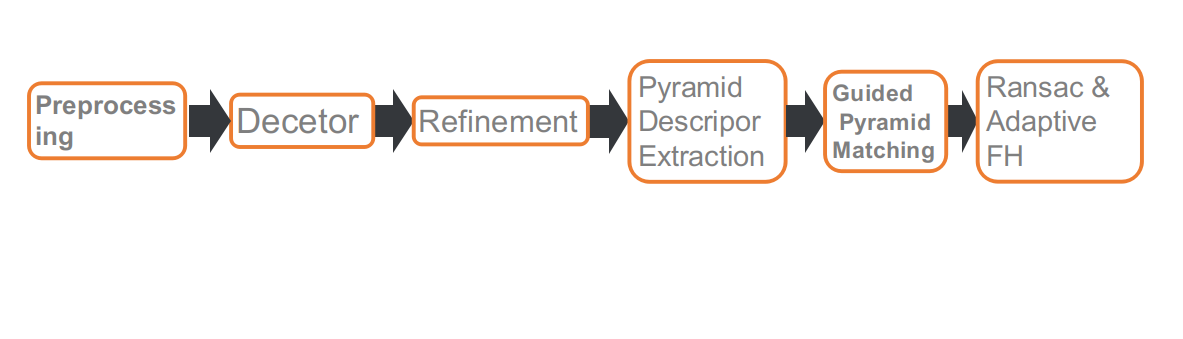
これは私たちのコンテストのパイプラインで、全部で6つの部分から構成されています。それぞれ、前処理、特徴点検出、特徴点位置のリファイン、多スケールまたは多角度でのディスクリプタ抽出、Guidedマッチング、そして適応型FHに基づいたRANSACです。
前処理


IMCトラックでは特徴点の数に制限があるため、特徴点の位置が非常に重要です。歩行者、車両、空などの動的な物体は、マッチングして姿勢を解くのに役立たないか、逆効果をもたらすことがあります。そのため、これらの物体をマスクするためにセグメンテーションネットワークを使用し、特徴点を抽出する際にマスク領域を無視します。
セグメンテーションネットワークを使用した前処理の後、2つの問題が発見されました。
- 1つ目は、セグメンテーションネットワークの精度が低いため、建物と空の接続領域をうまく区別できず、建物のエッジが破壊されることがあり、これがマッチングに不利な影響を与えます。そのため、動的な物体をマスクした後、マスク領域に腐食処理を施し、建物のエッジのディテールを保持します。
- もう1つの問題は、セグメンテーションネットワークアルゴリズムが人間と彫像を区別する汎化能力が低く、歩行者をマスクする際に彫像もマスクしてしまうことです。例えば、リンカーンデータセットのようなシーンでは、彫像上の特徴点がマッチング結果に重要な役割を果たします。この問題に対処するために、彫像と歩行者を区別する分類ネットワークを訓練し、歩行者を除去しつつ彫像を保持できるようにしました。
前処理操作により、Phototourism検証セットのStereoとMultiviewタスクでそれぞれ1.1%と0.3%の向上が見られました。
特徴点抽出
Adapt Homographic
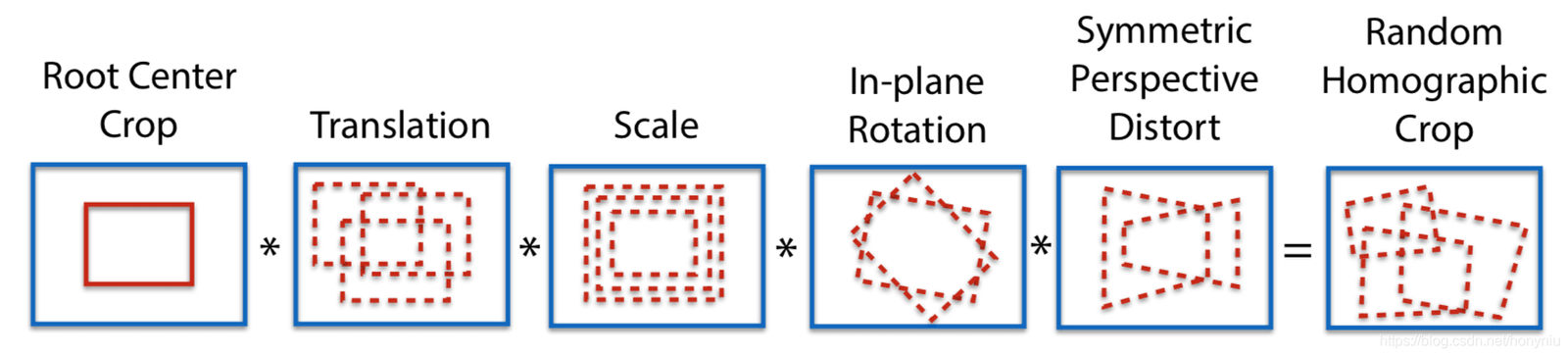
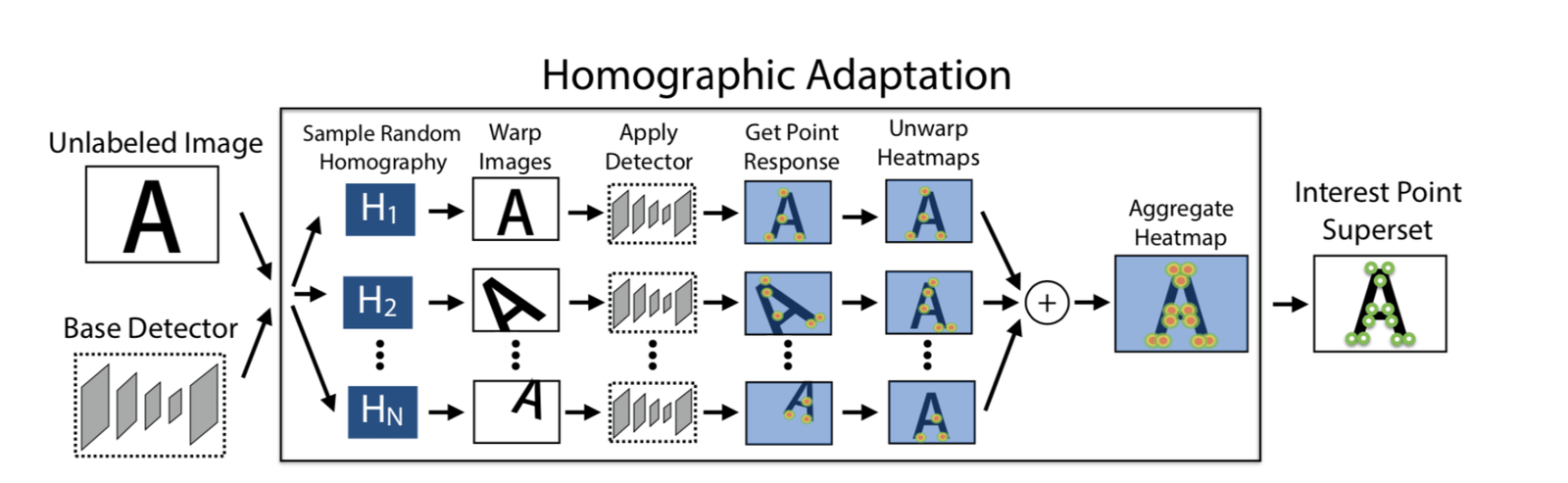
100回のホモグラフィ変換を使用して、変換後の100枚の画像を取得し、これらの画像上でSuperPointモデルを使用してそれぞれ特徴点を抽出します。n個の特徴点のヒートマップを取得し、これらのn個のヒートマップを重ね合わせて最終的なヒートマップを得て、必要に応じて特徴点を選択します。この方法の利点は、より多くの特徴点を抽出できることと、特徴点の位置がより合理的になることです。
Adapt Homographicを使用することで、Phototourism検証セットのStereoとMultiviewタスクでそれぞれ1.7%と1.3%の向上が見られました。
リファインメント
SuperPointで抽出された特徴点は整数であり、soft argmax refinementを使用し、半径2のパラメータを使用してサブピクセル化し、特徴点の位置をより正確にします。リファインメント手法を採用することで、Phototourism検証セットのStereoとMultiviewタスクでそれぞれ0.8%と0.35%の向上が見られました。
NMS

DISK特徴抽出法で抽出された特徴点を観察すると、特徴点が密集している場合があり、この結果、いくつかの領域に特徴点が存在しないことがあります。
このような状況を緩和するために、比較的大きな半径のNMSを使用し、NMSの半径を3から10に拡大しました。図からもわかるように、特徴点の密集が改善されました。PragueParks検証セットのStereoタスクでも0.57%の向上が見られました。
ピラミッドディスクリプタ&Guided Pyramid Matching
コーナーケースの分析


ベースラインを構築した後、テストセットからランダムにサンプリングし、いくつかの画像を選んでコーナーケースを分析しました。観察によると、マッチングの効果が悪い主な原因は2つの状況、またはこれら2つの状況が同時に発生することです。
- スケールの差が大きい
- 大きな角度の回転
これらのコーナーケースに対処するために、ピラミッドディスクリプタ抽出とGuidedマッチング戦略を採用しました。

異なるスケールや異なる角度で、同じ特徴点セットに基づいてディスクリプタを抽出します。つまり、特徴点は1枚の画像で抽出され、ディスクリプタは特徴点のマッピングに基づいて異なる画像で抽出されます。
マッチング時に閾値tを設定し、マッチング数が閾値tを超える場合は元のスケールまたは元の角度でマッチングし、閾値tを下回る場合は多スケールマッチングまたは多角度マッチングを使用します。
この修正により、上記のコーナーケースのマッチング効果が一定の改善を見せました。


この戦略により、3つのデータセットの検証セットのStereoとMultiviewタスクで平均0.4%の向上が見られました。
SuperGlueの再訓練
さらに、SuperGlueを再訓練しました。ここでは2つの側面があります。1つは、公式のSuperPoint+SuperGlue手法を再現することです。もう1つは、より効果的な特徴抽出手法であるDISKを使用して、DISK+SuperGlueを訓練することです。DISK+SuperGlueは、YFCC検証セットで公式のSuperPoint+SuperGlueよりも約4%高いパフォーマンスを示しました。
コンテストデータセットに対して、DISK+SuperGlueはPhototourismで良好なパフォーマンスを示しましたが、他の2つのデータセットでは効果が低く、これはDISKがMegadepthで訓練されたため、建物データセットに対して過剰適合していた可能性があります。一方、SuperPointはCOCOで訓練されており、COCOにはより多様なシーンが含まれているため、汎化能力が強いです。
最終的に、8kトラック(unlimited keypoints)では、SuperPoint+SuperGlueとDISK+SuperGlueをアンサンブルし、2つを単独で使用するよりも良い結果を得ました。
| Methods | Phototourism | PragueParks | GoogleUrban | |||
|---|---|---|---|---|---|---|
| Stereo | Multiview | Stereo | Multiview | Stereo | Multiview | |
| SP-SG(4K) | 0.60357 | 0.78290 | 0.79766 | 0.50499 | 0.41212 | 0.32472 |
| DISK-SG(8K) | 0.61955 ↑ | 0.77531 | 0.72002 | 0.48548 | 0.38764 | 0.26281 |
| SP-DISK-SG | 0.63975 ↑ | 0.78564 ↑ | 0.80700 ↑ | 0.49878 | 0.43952 ↑ | 0.33734 ↑ |
RANSAC&Adapt FH
まず、OpenCVのRANSAC、DEGENSAC、MAGSAC++など、さまざまなRANSAC手法を試しました。実験の結果、DEGENSACが最も効果的であることがわかりました。
また、DEGENSACはF行列を使用して解く際に、平面退化問題が発生することがあります。このような状況です。

平面退化問題に対処するために、ORB-SLAMのインスピレーションを受けて、適応型FH戦略を設計しました。具体的なアルゴリズムは次の通りです:

応用:ARナビゲーション
旷视は、最先端のアルゴリズムと実際のビジネスを結びつけることを非常に重視しており、この記事で紹介したImage Matching技術は、S800V SLAMロボットやARナビゲーションなど、複数のプロジェクトにすでに応用されています。
旷视のある「室内視覚位置決めナビゲーション」プロジェクトを例に挙げると、大規模なSfM疎点群再構築技術とImage Matching技術に依存して、旷视3Dチームはスマートフォンのカメラだけを使用して、複雑な室内シーンで正確な位置決めとARナビゲーションを実現しました。従来のGPSやBluetoothなどの室内位置決めソリューションと比較して、「室内視覚位置決めナビゲーション」は、センチメートル単位のマッピング精度、サブメートル単位の位置決め精度を持ち、室内シーンに追加のポイントを設置する必要がないため、顧客の「高精度、簡単な展開とメンテナンス」という室内位置決めの要件を満たし、すでにいくつかの大規模な室内シーンの室内位置決めナビゲーションプロジェクトで成功を収めています。
この技術をより直感的に体験できるように、室内視覚位置決めナビゲーションアプリ「MegGo」が旷視の内部でリリースされており、各工区の室内位置決めとナビゲーションをサポートしています。見知らぬ工区にいても、この電子「ガイド」を利用して、会議室などの目的地に迅速かつ正確にナビゲートできます。また、旷視を訪れる方々も、スマートフォンにMegGoをダウンロードして、工区内での位置決めとナビゲーションを体験することができます(以下の図は、MegGoを使用して視覚位置決めとARナビゲーションを行っている様子をそれぞれ示しています)。
[gif-player id="3304"]
視覚位置決め
[gif-player id="3305"]
ARナビゲーション
将来の展望
- トレーニング時に強化学習を追加し、パイプライン全体を再訓練することができます。
- DISKの汎化能力を強化し、より多くのデータセットを使用してトレーニングします。
- Refinementsネットワークを使用して、特徴点の位置をリファインします。
参考文献
1. D. DeTone, T. Malisiewicz, and A. Rabinovich, “SuperPoint: Self-supervised interest point detection and description,”CoRR, vol. abs/1712.07629, 2017.
2. M. Tyszkiewicz, P. Fua, and E. Trulls, “DISK: Learning local features with policy gradient,” Advances in Neural Informa-tion Processing Systems, vol. 33, 2020.
3. K. He, G. Gkioxari, P. Dollár, and R. B. Girshick,“Mask R-CNN,” CoRR, vol. abs/1703.06870, 2017.
4. H. Zhao, J. Shi, X. Qi, X. Wang, and J. Jia, “Pyramid scene parsing network,” in CVPR, 2017.
5. P.-E. Sarlin, D. DeTone, T. Malisiewicz, and A. Rabinovich, “SuperGlue: Learning feature matching with graph neural networks,” in CVPR, 2020.
6. D. Mishkin, J. Matas, and M. Perdoch, “Mods: Fast and robust method for two-view matching,” Computer Vision and Image Understanding, 2015.
7. C. Campos, R. Elvira, J. J. Gomez, J. M. M. Montiel, および J. D. Tardós, 「ORB-SLAM3: 視覚、視覚慣性、およびマルチマップSLAMのための正確なオープンソースライブラリ」, arXiv preprint arXiv:2007.11898, 2020.