Revue de l'algorithme double champion du défi de correspondance d'images CVPR 2021
En s'appuyant sur les articles que nous avons précédemment fournis à l'entreprise, résumons quelques expériences et réflexions récentes sur la compétition. Tous droits réservés : Megvii Technology. Lien vers l'article original : https://www.zhihu.com/question/32066833/answer/2041516754
Image Matching (Correspondance d'images) est l'une des technologies fondamentales dans le domaine de la vision par ordinateur. Elle consiste à associer les informations locales des mêmes positions dans deux images, soit par correspondance de caractéristiques rares ou denses. L'Image Matching est largement utilisée dans de nombreux domaines, tels que la robotique, les voitures autonomes, la réalité augmentée/virtuelle (AR/VR), la recherche d'images/produits, la reconnaissance d'empreintes digitales, etc.
Lors de la compétition Image Matching de CVPR 2021 qui vient de se terminer, l'équipe 3D de Megvii a remporté deux premières places et une deuxième place. Cet article présente leur stratégie de compétition, leurs expériences et quelques réflexions.



Présentation de la compétition
La correspondance d'images consiste à identifier et aligner au niveau des pixels les contenus ou structures ayant des attributs identiques ou similaires dans deux images. En général, les images à faire correspondre proviennent de scènes ou d'objets similaires, ou d'autres types d'images ayant des formes ou des informations sémantiques identiques, ce qui leur confère une certaine compatibilité pour la correspondance.
Image Matching Challenge

Le concours Image Matching Challenge (IMC) est divisé en deux pistes : unlimited keypoints et restricted keypoints, où le nombre de points de caractéristiques extraits par image est respectivement inférieur à 8k et 2k.
Cette année, la compétition IMC comportait trois ensembles de données : Phototourism, PragueParks et GoogleUrban. Ces ensembles de données sont très différents, ce qui impose des exigences élevées en termes de capacité de généralisation des algorithmes. Les organisateurs espéraient trouver une méthode qui fonctionne bien sur les trois ensembles de données, le classement final étant basé sur la moyenne des classements des trois ensembles.
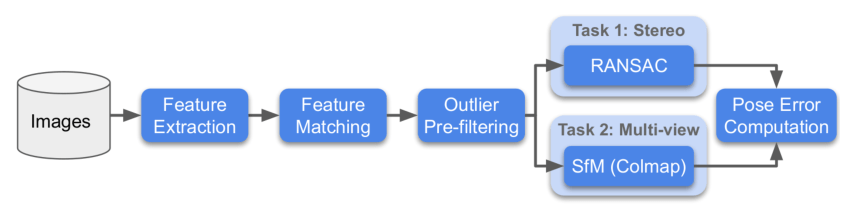
Pour chaque ensemble de données, les organisateurs ont utilisé deux méthodes d'évaluation : Stereo et Multiview, puis ont calculé le classement pour ces deux tâches.
- Stereo : Correspondance entre deux images, puis résolution de la matrice F pour calculer l'erreur de pose réelle.
- Multiview : Sélection d'un petit nombre d'images pour former des "bags", construction de cartes à partir de ces "bags", et résolution de l'erreur de pose entre différentes images à partir du modèle 3D.
Voici le diagramme du processus de la compétition :
SimLoc Match

SimLoc est également un ensemble de données comprenant différents types de scènes. Contrairement aux ensembles de données IMC, il s'agit d'un ensemble de données synthétiques, permettant d'obtenir une ground truth entièrement précise.
La compétition comporte trois indicateurs, et le taux de correspondance réussi est utilisé comme indicateur final de classement. Les trois indicateurs sont :
- Nombre de points internes (plus c'est élevé, mieux c'est)
- Taux de correspondance réussi, c'est-à-dire le nombre de points internes correspondants / toutes les paires correspondantes fournies (plus c'est élevé, mieux c'est)
- Nombre de correspondances négatives, c'est-à-dire que lorsque deux images n'ont pas de zone de vue commune, le nombre de correspondances doit être aussi faible que possible
Stratégie
Analyse des données


Nous avons d'abord analysé les trois ensembles de données de la compétition.
- Observer s'il existe un écart entre l'ensemble de validation et l'ensemble de test
- Déterminer la taille de redimensionnement en mesurant les longueurs et largeurs de chaque ensemble de données
Pipeline
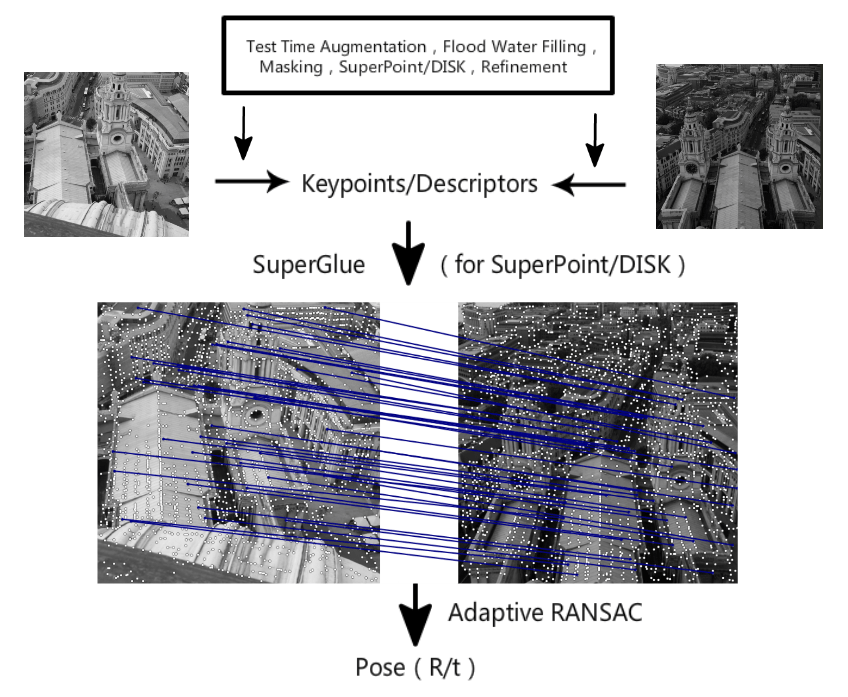
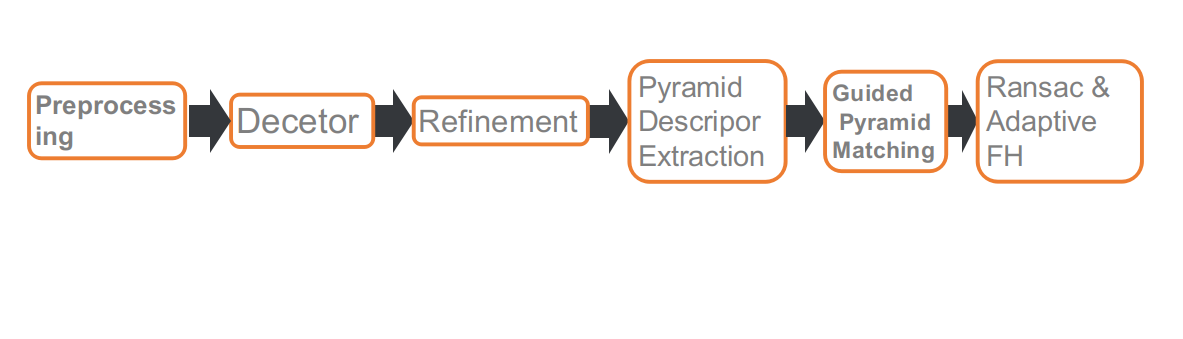
Voici notre pipeline de compétition, qui comprend six parties : prétraitement, détection des points de caractéristiques, affinement de la position des points de caractéristiques, extraction de descripteurs multi-échelle ou multi-angle, correspondance guidée et RANSAC basé sur FH adaptatif.
Prétraitement


La piste IMC impose des restrictions sur le nombre de points de caractéristiques, ce qui rend la position des points de caractéristiques particulièrement importante. Certains objets dynamiques, comme les piétons, les véhicules, le ciel, etc., n'ont aucune utilité pour la résolution de la pose ou peuvent même avoir un effet négatif. Nous avons donc utilisé un réseau de segmentation pour masquer ces objets, de sorte que lors de l'extraction des points de caractéristiques, les zones masquées soient ignorées.
Après avoir utilisé le réseau de segmentation pour le prétraitement, nous avons découvert deux problèmes.
- Le premier est que la précision du réseau de segmentation n'est pas très élevée, ce qui ne permet pas de bien distinguer la zone de connexion entre les bâtiments et le ciel, ce qui peut endommager les bords des bâtiments, ce qui n'est pas favorable à la correspondance. Après avoir masqué les objets dynamiques, nous avons donc appliqué une érosion aux zones masquées afin de préserver les détails des bords des bâtiments.
- Le deuxième problème est que l'algorithme du réseau de segmentation n'a pas une bonne capacité de généralisation pour distinguer les humains des statues. Lorsque nous masquons les piétons, les statues sont également masquées. Cependant, dans certains ensembles de données, comme celui de Lincoln, les points de caractéristiques sur les statues sont importants pour les résultats de la correspondance. Pour résoudre ce problème, nous avons entraîné un réseau de classification pour distinguer les statues des piétons, ce qui permet de masquer les piétons tout en conservant les statues.
Grâce à ces opérations de prétraitement, nous avons amélioré les performances de 1,1 % et 0,3 % respectivement sur les tâches Stereo et Multiview de l'ensemble de validation Phototourism.
Extraction des points de caractéristiques
Adapt Homographic
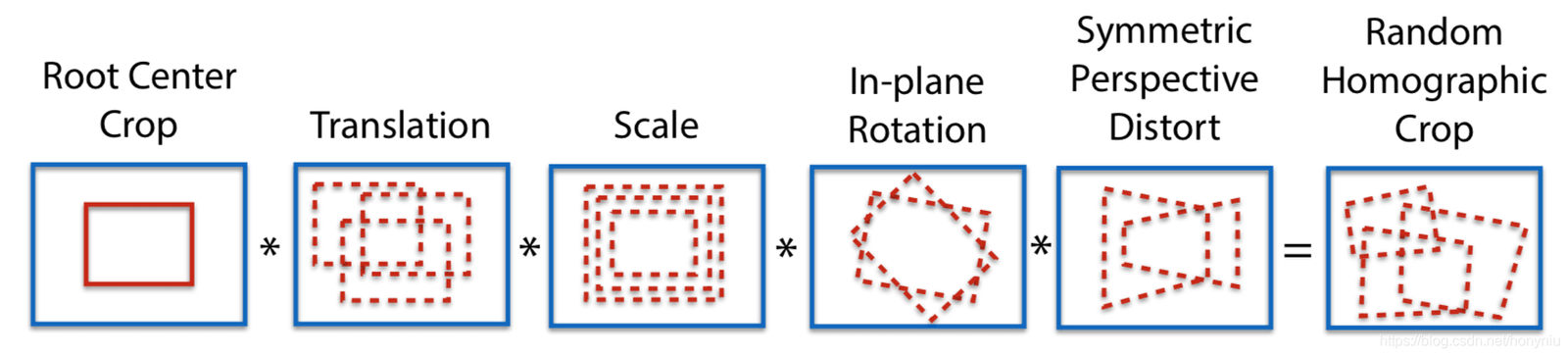
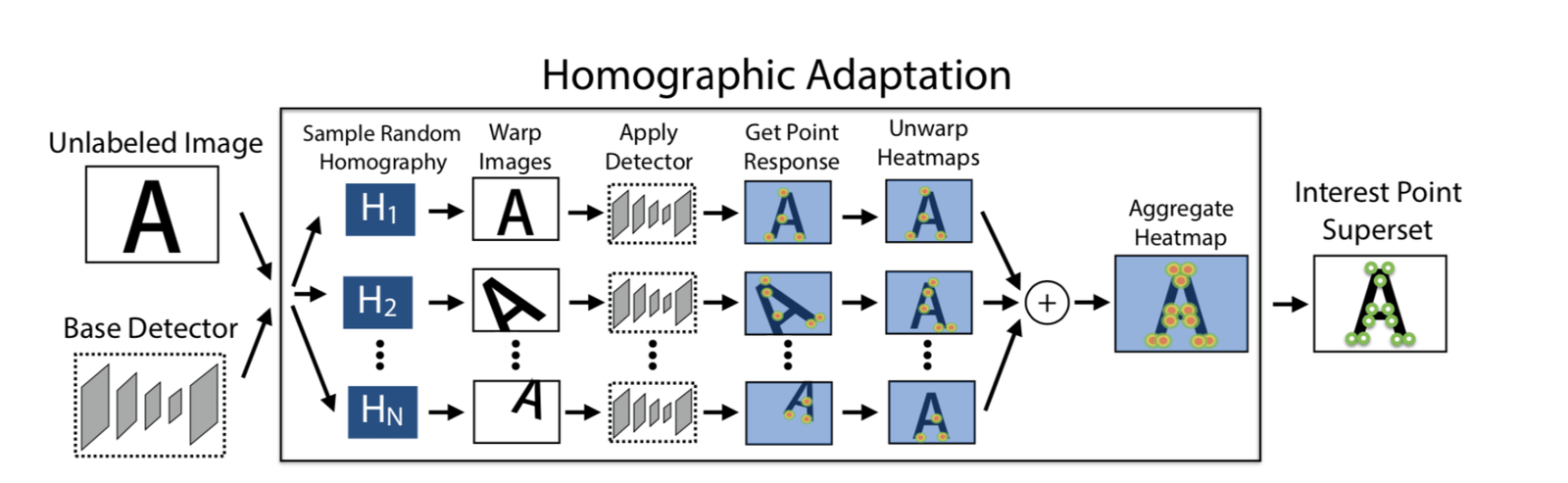
Nous avons utilisé 100 transformations de matrice homographique pour obtenir 100 images transformées. Sur ces images, nous avons utilisé le modèle SuperPoint pour extraire les points de caractéristiques, obtenant ainsi n cartes thermiques de points de caractéristiques. En superposant ces n cartes thermiques, nous avons obtenu la carte thermique finale, puis sélectionné les points de caractéristiques en fonction des besoins. Cette méthode permet d'extraire plus de points de caractéristiques et de rendre leur position plus précise.
En utilisant l'Adapt Homographic, nous avons amélioré les performances de 1,7 % et 1,3 % respectivement sur les tâches Stereo et Multiview de l'ensemble de validation Phototourism.
Affinement
Les points de caractéristiques extraits par SuperPoint sont des entiers. Nous avons utilisé un affinement soft argmax avec un paramètre de rayon de 2 pour obtenir une précision subpixel, ce qui rend la position des points de caractéristiques plus précise. En utilisant cette méthode d'affinement, nous avons amélioré les performances de 0,8 % et 0,35 % respectivement sur les tâches Stereo et Multiview de l'ensemble de validation Phototourism.
NMS

En observant la méthode DISK d'extraction des points de caractéristiques, nous avons remarqué que les points de caractéristiques étaient souvent concentrés dans certaines zones, ce qui laissait d'autres zones sans points de caractéristiques.
Pour atténuer ce problème, nous avons utilisé un NMS avec un rayon plus grand, en passant d'un rayon de 3 à un rayon de 10. Comme le montre l'image, la concentration des points de caractéristiques a été améliorée. Sur la tâche Stereo de l'ensemble de validation PragueParks, nous avons également obtenu une amélioration de 0,57 %.
Descripteur pyramidal et correspondance pyramidale guidée
Analyse des cas limites


Après avoir mis en place la ligne de base, nous avons effectué un échantillonnage aléatoire dans l'ensemble de test et sélectionné certaines images pour analyser les cas limites. Nous avons observé que les mauvais résultats de correspondance étaient principalement dus à deux situations, ou parfois à une combinaison des deux :
- Grande différence d'échelle
- Rotation à grand angle
Pour résoudre ces cas limites, nous avons adopté une stratégie d'extraction de descripteurs pyramidaux et de correspondance guidée.

Nous avons extrait des descripteurs à différentes échelles et angles à partir des mêmes points de caractéristiques, c'est-à-dire que les points de caractéristiques sont extraits d'une seule image, et les descripteurs sont extraits en fonction de la projection des points de caractéristiques sur différentes images.
Lors de la correspondance, nous avons défini un seuil t. Si le nombre de correspondances est supérieur au seuil t, nous utilisons la correspondance à l'échelle ou à l'angle d'origine. Si le nombre de correspondances est inférieur au seuil t, nous utilisons la correspondance multi-échelle ou multi-angle.
Grâce à cette correction, les résultats de correspondance pour les cas limites ont été améliorés.


Grâce à cette stratégie, nous avons amélioré les performances moyennes de 0,4 % sur les tâches Stereo et Multiview des ensembles de validation des trois ensembles de données.
Retrain SuperGlue
Nous avons également réentraîné SuperGlue, avec deux objectifs. Le premier était de reproduire la méthode officielle SuperPoint+SuperGlue. Le second était d'utiliser une méthode d'extraction de caractéristiques plus performante, DISK, pour entraîner DISK+SuperGlue. DISK+SuperGlue a surpassé SuperPoint+SuperGlue d'environ 4 % sur l'ensemble de validation YFCC.
Pour les ensembles de données de la compétition, DISK+SuperGlue a bien fonctionné sur Phototourism, mais a donné de moins bons résultats sur les deux autres ensembles de données, probablement parce que DISK a été entraîné sur Megadepth et est sur-ajusté aux ensembles de données de bâtiments. SuperPoint, quant à lui, a été entraîné sur COCO, qui contient des scènes plus variées, ce qui lui confère une meilleure capacité de généralisation.
Enfin, sur la piste 8k (unlimited keypoints), nous avons combiné SuperPoint+SuperGlue et DISK+SuperGlue, et les résultats ont été meilleurs que ceux obtenus en utilisant l'un ou l'autre séparément.
| Methods | Phototourism | PragueParks | GoogleUrban | |||
|---|---|---|---|---|---|---|
| Stereo | Multiview | Stereo | Multiview | Stereo | Multiview | |
| SP-SG(4K) | 0.60357 | 0.78290 | 0.79766 | 0.50499 | 0.41212 | 0.32472 |
| DISK-SG(8K) | 0.61955 ↑ | 0.77531 | 0.72002 | 0.48548 | 0.38764 | 0.26281 |
| SP-DISK-SG | 0.63975 ↑ | 0.78564 ↑ | 0.80700 ↑ | 0.49878 | 0.43952 ↑ | 0.33734 ↑ |
RANSAC et Adapt FH
Nous avons d'abord essayé plusieurs méthodes RANSAC, telles que la méthode RANSAC intégrée à OpenCV, la méthode DEGENSAC et la méthode MAGSAC++. Après expérimentation, nous avons constaté que DEGENSAC donnait les meilleurs résultats.
Cependant, lors de l'utilisation de DEGENSAC pour résoudre la matrice F, nous avons rencontré des problèmes de dégénérescence plane, comme illustré ci-dessous.

Pour résoudre ce problème de dégénérescence plane, inspirés par ORB-SLAM, nous avons conçu une stratégie FH adaptative. L'algorithme spécifique est le suivant :

Application : Navigation AR
Megvii attache une grande importance à la combinaison des algorithmes de pointe avec les applications commerciales réelles. La technologie Image Matching présentée dans cet article a déjà été appliquée dans plusieurs projets, tels que le robot SLAM S800V et la navigation AR.
Prenons l'exemple d'un projet de "localisation et navigation visuelle en intérieur" de Megvii. Grâce à la technologie de reconstruction de nuages de points 3D SfM à grande échelle et à la technologie Image Matching, l'équipe 3D de Megvii a réussi à permettre une localisation précise et une navigation AR dans des environnements intérieurs complexes, uniquement à l'aide de la caméra d'un téléphone portable. Par rapport aux solutions de localisation intérieure traditionnelles telles que le GPS ou le Bluetooth, la "localisation et navigation visuelle en intérieur" offre une précision de cartographie au centimètre près, une précision de localisation au mètre près, et ne nécessite pas de balises supplémentaires dans l'environnement intérieur, répondant ainsi aux exigences des clients en matière de "haute précision et facilité de déploiement et de maintenance". Cette technologie a déjà remporté plusieurs appels d'offres pour des projets de navigation intérieure dans de grands environnements intérieurs.
Pour offrir une expérience plus intuitive de cette technologie, l'application de navigation visuelle en intérieur, "MegGo", a été lancée en interne chez Megvii. Elle prend en charge la localisation et la navigation dans les différents sites de l'entreprise. Même si vous vous trouvez dans un site inconnu, vous pouvez utiliser ce "guide électronique" pour naviguer rapidement et précisément jusqu'à des destinations telles que des salles de réunion. Les visiteurs de Megvii peuvent également télécharger MegGo sur leur téléphone pour découvrir la localisation et la navigation dans les sites de l'entreprise (les images ci-dessous montrent respectivement la localisation visuelle et la navigation AR avec MegGo).
[gif-player id="3304"]
Localisation visuelle
[gif-player id="3305"]
Navigation AR
Perspectives
- Ajouter un apprentissage par renforcement lors de l'entraînement et réentraîner l'ensemble du pipeline.
- Améliorer la capacité de généralisation de DISK en utilisant davantage d'ensembles de données pour l'entraînement.
- Utiliser des réseaux d'affinement pour affiner la position des points de caractéristiques.
Références
1. D. DeTone, T. Malisiewicz, et A. Rabinovich, “SuperPoint: Self-supervised interest point detection and description,”CoRR, vol. abs/1712.07629, 2017.
2. M. Tyszkiewicz, P. Fua, et E. Trulls, “DISK: Learning local features with policy gradient,” Advances in Neural Information Processing Systems, vol. 33, 2020.
3. K. He, G. Gkioxari, P. Dollár, et R. B. Girshick,“Mask R-CNN,” CoRR, vol. abs/1703.06870, 2017.
4. H. Zhao, J. Shi, X. Qi, X. Wang, et J. Jia, “Pyramid scene parsing network,” in CVPR, 2017.
5. P.-E. Sarlin, D. DeTone, T. Malisiewicz, et A. Rabinovich, “SuperGlue: Learning feature matching with graph neural networks,” in CVPR, 2020.
6. D. Mishkin, J. Matas, et M. Perdoch, “Mods: Fast and robust method for two-view matching,” Computer Vision and Image Understanding, 2015.
7. C. Campos, R. Elvira, J. J. Gomez, J. M. M. Montiel, et J. D. Tardós, « ORB-SLAM3 : Une bibliothèque open-source précise pour le SLAM visuel, visuo-inertiel et multi-cartes », arXiv preprint arXiv:2007.11898, 2020.
Revue de l'algorithme double champion du défi de correspondance d'images CVPR 2021
En nous basant sur les articles que nous avons précédemment fournis à l'entreprise, résumons quelques expériences et réflexions des récentes compétitions. Tous droits réservés : Megvii Technology. Lien vers l'article original : https://www.zhihu.com/question/32066833/answer/2041516754
Image Matching (Correspondance d'images) est l'une des technologies fondamentales dans le domaine de la vision par ordinateur. Elle consiste à associer les informations locales des mêmes positions dans deux images à l'aide de correspondances de caractéristiques rares ou denses. L'Image Matching est largement utilisée dans de nombreux domaines, tels que la robotique, les voitures autonomes, la réalité augmentée/virtuelle (AR/VR), la recherche d'images/produits, la reconnaissance d'empreintes digitales, etc.
Lors de la compétition Image Matching de CVPR 2021 qui vient de se terminer, l'équipe 3D de Megvii a remporté deux premières places et une deuxième place. Cet article présente leur stratégie de compétition, leurs expériences et quelques réflexions.
Présentation de la compétition
L'Image Matching consiste à identifier et aligner les pixels de deux images ayant des contenus ou des structures similaires ou identiques. En général, les images à faire correspondre proviennent de scènes ou d'objets similaires, ou d'autres types d'images ayant des formes ou des informations sémantiques similaires, ce qui leur confère une certaine compatibilité.
Image Matching Challenge
Le concours Image Matching Challenge (IMC) de cette année était divisé en deux pistes : unlimited keypoints et restricted keypoints, c'est-à-dire que le nombre de points caractéristiques extraits par image était respectivement inférieur à 8k et 2k.
Cette année, la compétition IMC comportait trois ensembles de données : Phototourism, PragueParks et GoogleUrban. Ces trois ensembles de données sont assez différents, ce qui exige une grande capacité de généralisation des algorithmes. Les organisateurs espéraient trouver une méthode qui fonctionne bien sur les trois ensembles de données, de sorte que le classement final soit la moyenne des classements sur ces trois ensembles.
Pour chaque ensemble de données, les organisateurs ont utilisé deux méthodes d'évaluation : Stereo et Multiview, puis ont calculé le classement pour ces deux tâches.
- Stereo : correspondance entre deux images, puis résolution de la matrice F pour calculer l'erreur de pose réelle.
- Multiview : sélection d'un petit nombre d'images pour former des "bags", construction de cartes à partir de ces "bags", et résolution de l'erreur de pose entre différentes images à l'aide d'un modèle 3D.
Voici le diagramme de flux de la compétition :
SimLoc Match
SimLoc est également un ensemble de données contenant différents types de scènes. Contrairement à l'ensemble de données IMC, il s'agit d'un ensemble de données synthétiques, ce qui permet d'obtenir un ground truth parfaitement précis.
La compétition comporte trois indicateurs, et le taux de correspondance réussi est utilisé comme critère final de classement. Les trois indicateurs sont :
- Nombre d'inliers (plus c'est élevé, mieux c'est)
- Taux de correspondance réussi, c'est-à-dire le nombre d'inliers / toutes les paires de correspondances fournies (plus c'est élevé, mieux c'est)
- Nombre de correspondances négatives, lorsque deux images n'ont pas de zone de vision commune, le nombre de correspondances doit être aussi faible que possible
Stratégie
Analyse des données
Tout d'abord, nous avons analysé les trois ensembles de données de la compétition.
- Observer s'il existe un écart entre l'ensemble de validation et l'ensemble de test
- Déterminer la taille de redimensionnement en fonction des dimensions de chaque ensemble de données
Pipeline
Voici notre pipeline de compétition, qui comprend six parties : prétraitement, détection des points caractéristiques, affinement de la position des points caractéristiques, extraction de descripteurs à plusieurs échelles ou angles, correspondance guidée et RANSAC basé sur FH adaptatif.
Prétraitement
La piste IMC impose une limite au nombre de points caractéristiques, ce qui rend la position des points caractéristiques particulièrement importante. Certains objets dynamiques, tels que les piétons, les véhicules, le ciel, etc., n'ont pas d'impact sur la résolution de la pose ou peuvent même avoir un effet négatif. Nous avons donc utilisé un réseau de segmentation pour masquer ces objets, de sorte que les zones masquées soient ignorées lors de l'extraction des points caractéristiques.
Après avoir utilisé le réseau de segmentation pour le prétraitement, nous avons découvert deux problèmes.
- Le premier est que la précision du réseau de segmentation n'est pas très élevée, ce qui ne permet pas de bien distinguer les zones de connexion entre les bâtiments et le ciel, ce qui peut endommager les bords des bâtiments, ce qui n'est pas favorable à la correspondance. Par conséquent, après avoir masqué les objets dynamiques, nous avons appliqué une érosion aux zones masquées pour préserver les détails des bords des bâtiments.
- Le deuxième problème est que le réseau de segmentation ne généralise pas bien entre les humains et les statues. Lorsqu'il masque les piétons, il masque également les statues. Cependant, dans certains ensembles de données, comme celui de Lincoln, les points caractéristiques sur les statues sont importants pour la correspondance. Pour résoudre ce problème, nous avons entraîné un réseau de classification pour distinguer les statues des piétons, ce qui nous permet de supprimer les piétons tout en conservant les statues.
Grâce à ces opérations de prétraitement, nous avons amélioré les performances de 1,1 % et 0,3 % respectivement sur les tâches Stereo et Multiview de l'ensemble de validation Phototourism.
Extraction des points caractéristiques
Adapt Homographic
Nous avons appliqué 100 transformations homographiques pour obtenir 100 images transformées. Sur ces images, nous avons utilisé le modèle SuperPoint pour extraire les points caractéristiques, ce qui nous a permis d'obtenir n cartes de chaleur de points caractéristiques. En superposant ces n cartes de chaleur, nous avons obtenu une carte de chaleur finale, à partir de laquelle nous avons sélectionné les points caractéristiques nécessaires. Cette méthode permet d'extraire plus de points caractéristiques et de rendre leur position plus précise.
En utilisant l'Adapt Homographic, nous avons amélioré les performances de 1,7 % et 1,3 % respectivement sur les tâches Stereo et Multiview de l'ensemble de validation Phototourism.
Affinement
Les points caractéristiques extraits par SuperPoint sont des entiers. Nous avons utilisé un affinement soft argmax avec un rayon de 2 pour obtenir une précision subpixel, ce qui rend la position des points caractéristiques plus précise. En utilisant cette méthode d'affinement, nous avons amélioré les performances de 0,8 % et 0,35 % respectivement sur les tâches Stereo et Multiview de l'ensemble de validation Phototourism.
NMS
En observant la méthode DISK pour l'extraction des points caractéristiques, nous avons constaté que les points caractéristiques étaient souvent regroupés de manière dense, ce qui entraînait l'absence de points caractéristiques dans certaines zones.
Pour atténuer ce problème, nous avons utilisé un rayon NMS plus grand, en passant de 3 à 10. Comme le montre l'image, la densité des points caractéristiques a été améliorée. Sur la tâche Stereo de l'ensemble de validation PragueParks, nous avons également obtenu une amélioration de 0,57 %.
Descripteur pyramidal && Correspondance pyramidale guidée
Analyse des cas limites
Après avoir mis en place la ligne de base, nous avons échantillonné aléatoirement certaines images de l'ensemble de test pour analyser les cas limites. Nous avons observé que les mauvais résultats de correspondance étaient principalement dus à deux situations, ou à une combinaison des deux :
- Grande différence d'échelle
- Rotation à grand angle
Pour résoudre ces cas limites, nous avons adopté une stratégie d'extraction de descripteurs pyramidaux et de correspondance guidée.
Nous avons extrait des descripteurs à différentes échelles et angles à partir du même ensemble de points caractéristiques. Les points caractéristiques sont extraits d'une seule image, et les descripteurs sont extraits en fonction de la projection des points caractéristiques sur différentes images.
Lors de la correspondance, nous avons défini un seuil t. Si le nombre de correspondances est supérieur au seuil t, nous utilisons la correspondance à l'échelle ou à l'angle d'origine. Si le nombre de correspondances est inférieur au seuil t, nous utilisons la correspondance multi-échelle ou multi-angle.
Grâce à cette correction, les résultats de correspondance pour les cas limites ont été améliorés.
Grâce à cette stratégie, nous avons amélioré les performances moyennes de 0,4 % sur les tâches Stereo et Multiview des trois ensembles de validation.
Retrain SuperGlue
Nous avons également réentraîné SuperGlue, ce qui s'est reflété dans deux aspects. Premièrement, nous avons reproduit la méthode officielle SuperPoint+SuperGlue. Deuxièmement, nous avons utilisé la méthode d'extraction de caractéristiques DISK, qui donne de meilleurs résultats, et entraîné DISK+SuperGlue. DISK+SuperGlue a surpassé SuperPoint+SuperGlue d'environ 4 % sur l'ensemble de validation YFCC.
Pour les ensembles de données de la compétition, DISK+SuperGlue a bien fonctionné sur Phototourism, mais a donné de moins bons résultats sur les deux autres ensembles de données, probablement parce que DISK a été entraîné sur Megadepth, ce qui a conduit à un surapprentissage sur les ensembles de données de bâtiments. SuperPoint, en revanche, a été entraîné sur COCO, qui contient des scènes plus variées, ce qui lui confère une meilleure capacité de généralisation.
Enfin, sur la piste 8k (unlimited keypoints), nous avons effectué un ensemble de SuperPoint+SuperGlue et DISK+SuperGlue, ce qui a donné de meilleurs résultats que l'utilisation de l'un ou l'autre séparément.
| Methods | Phototourism | PragueParks | GoogleUrban | |||
|---|---|---|---|---|---|---|
| Stereo | Multiview | Stereo | Multiview | Stereo | Multiview | |
| SP-SG(4K) | 0.60357 | 0.78290 | 0.79766 | 0.50499 | 0.41212 | 0.32472 |
| DISK-SG(8K) | 0.61955 ↑ | 0.77531 | 0.72002 | 0.48548 | 0.38764 | 0.26281 |
| SP-DISK-SG | 0.63975 ↑ | 0.78564 ↑ | 0.80700 ↑ | 0.49878 | 0.43952 ↑ | 0.33734 ↑ |
RANSAC && Adapt FH
Nous avons d'abord essayé plusieurs méthodes RANSAC, telles que la méthode RANSAC d'OpenCV, la méthode DEGENSAC et la méthode MAGSAC++. Les expériences ont montré que DEGENSAC donnait les meilleurs résultats.
De plus, lors de l'utilisation de DEGENSAC pour résoudre la matrice F, nous avons rencontré des problèmes de dégénérescence plane, comme illustré ci-dessous.
Pour résoudre ce problème de dégénérescence plane, nous nous sommes inspirés d'ORB-SLAM et avons conçu une stratégie FH adaptative. L'algorithme spécifique est illustré ci-dessous :
Application : Navigation AR
Megvii accorde une grande importance à l'intégration des algorithmes de pointe dans les applications commerciales. La technologie Image Matching présentée dans cet article a déjà été appliquée dans plusieurs projets, tels que le robot SLAM S800V et la navigation AR.
Prenons l'exemple d'un projet de "navigation visuelle intérieure" de Megvii. Grâce à la technologie de reconstruction de nuages de points 3D SfM et à la technologie Image Matching, l'équipe 3D de Megvii a réussi à permettre une localisation précise et une navigation AR dans des environnements intérieurs complexes en utilisant uniquement la caméra d'un smartphone. Par rapport aux solutions de localisation intérieure traditionnelles, telles que le GPS ou le Bluetooth, la "navigation visuelle intérieure" offre une précision de cartographie au centimètre près, une précision de localisation au mètre près, et ne nécessite pas de balises supplémentaires dans l'environnement intérieur. Cela répond aux exigences des clients en matière de "haute précision et de facilité de déploiement et de maintenance" pour la localisation intérieure. Ce projet a déjà remporté plusieurs contrats pour des projets de navigation intérieure dans de grands environnements intérieurs.
Pour offrir une expérience plus intuitive de cette technologie, l'application de navigation visuelle intérieure "MegGo" a été lancée en interne chez Megvii. Elle prend en charge la localisation et la navigation dans les différents sites de l'entreprise. Même dans un site inconnu, vous pouvez utiliser ce "guide électronique" pour vous rendre rapidement et précisément à des destinations telles que des salles de réunion. Les visiteurs de Megvii peuvent également télécharger MegGo sur leur téléphone pour découvrir la localisation et la navigation dans les sites de l'entreprise (les images ci-dessous montrent respectivement la localisation visuelle et la navigation AR avec MegGo).
[gif-player id="3304"]
Localisation visuelle
[gif-player id="3305"]
Navigation AR
Perspectives d'avenir
- Ajouter un apprentissage par renforcement lors de l'entraînement pour réentraîner l'ensemble du pipeline.
- Améliorer la capacité de généralisation de DISK en utilisant davantage d'ensembles de données pour l'entraînement.
- Utiliser des réseaux d'affinement pour affiner la position des points caractéristiques.
Références
1. D. DeTone, T. Malisiewicz, et A. Rabinovich, “SuperPoint: Self-supervised interest point detection and description,”CoRR, vol. abs/1712.07629, 2017.
2. M. Tyszkiewicz, P. Fua, et E. Trulls, “DISK: Learning local features with policy gradient,” Advances in Neural Informa-tion Processing Systems, vol. 33, 2020.
3. K. He, G. Gkioxari, P. Dollár, et R. B. Girshick,“Mask R-CNN,” CoRR, vol. abs/1703.06870, 2017.
4. H. Zhao, J. Shi, X. Qi, X. Wang, et J. Jia, “Pyramid scene parsing network,” in CVPR, 2017.
5. P.-E. Sarlin, D. DeTone, T. Malisiewicz, et A. Rabinovich, “SuperGlue: Learning feature matching with graph neural networks,” in CVPR, 2020.
6. D. Mishkin, J. Matas, et M. Perdoch, “Mods: Fast and robust method for two-view matching,” Computer Vision and Image Understanding, 2015.
7. C. Campos, R. Elvira, J. J. Gomez, J. M. M. Montiel, et J. D.Tardós, « ORB-SLAM3 : Une bibliothèque open-source précise pour le SLAM visuel, visuo-inertiel et multi-cartes », arXiv preprint arXiv:2007.11898, 2020.
Add a Comment