CVPR 2021 Image Matching Challenge Double Champion Algorithm Review
Using the article we previously provided to the company, let's summarize some experiments and thoughts from the recent competition. This article is copyrighted by Megvii Technology. Original link: https://www.zhihu.com/question/32066833/answer/2041516754
Image Matching is one of the most fundamental technologies in the field of computer vision. It refers to associating local information at the same positions in two images through sparse or dense feature matching. Image Matching has a wide range of applications in many fields, such as robotics, autonomous vehicles, AR/VR, image/product retrieval, fingerprint recognition, and more.
In the recently concluded CVPR 2021 Image Matching competition, the Megvii 3D team won two championships and one runner-up. This article introduces their competition approach, experiments, and some reflections.



Competition Introduction
Image matching refers to the pixel-level recognition and alignment of content or structures in two images that have the same or similar attributes. Generally, the images to be matched are usually taken from the same or similar scenes or targets, or other types of image pairs with the same shape or semantic information, making them somewhat matchable.
Image Matching Challenge

This Image Matching Challenge (IMC) competition was divided into two tracks: unlimited keypoints and restricted keypoints, where the number of feature points extracted per image is limited to less than 8k and 2k, respectively.
This year's IMC competition had three datasets: Phototourism, PragueParks, and GoogleUrban. These datasets are quite different, requiring high generalization ability from the algorithms. The organizers aimed to find a method that performs well across all three datasets, so the final ranking was based on the average ranking across the three datasets.
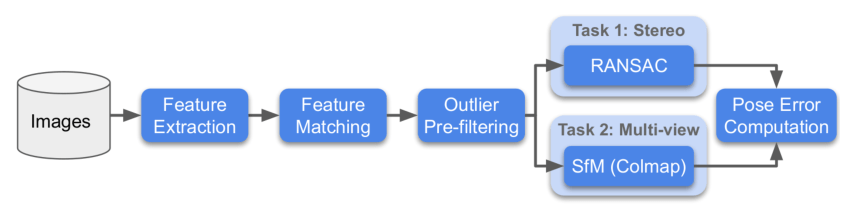
For each dataset, the organizers used two methods for evaluation: Stereo and Multiview, and then calculated the rank for these two tasks separately.
- Stereo: Matching two images and then solving the F matrix to calculate the actual pose error.
- Multiview: Selecting a small number of images to form a bag, building a map through the bag, and solving the pose error between different images using a 3D model.
Below is the competition flowchart:
SimLoc Match

SimLoc also contains datasets from different scenes. Unlike the IMC dataset, it is a synthetic dataset, allowing for completely accurate ground truth.
The competition had three metrics, with the final ranking based on the matching success rate. The three metrics are:
- Number of inliers (the higher, the better)
- Matching success rate, i.e., the number of inliers/total provided matching pairs (the higher, the better)
- Number of negative matches, where the fewer matches, the better when two images have no common view area
Solution
Data Analysis


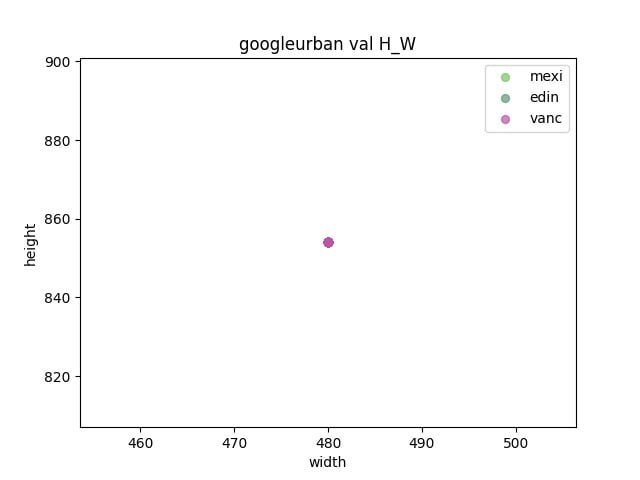
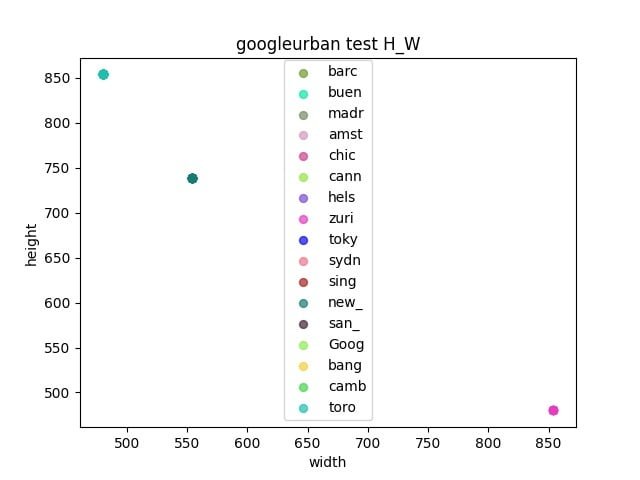
First, we analyzed the three datasets used in the competition.
- Observe whether there is a gap between the validation set and the test set
- Determine the resize size by calculating the width and height of each dataset
Pipeline
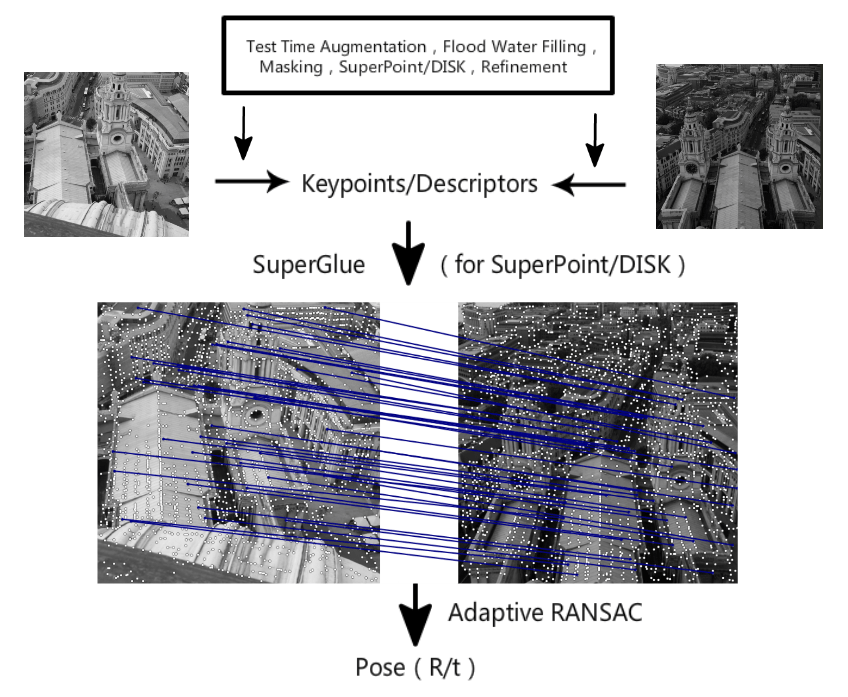
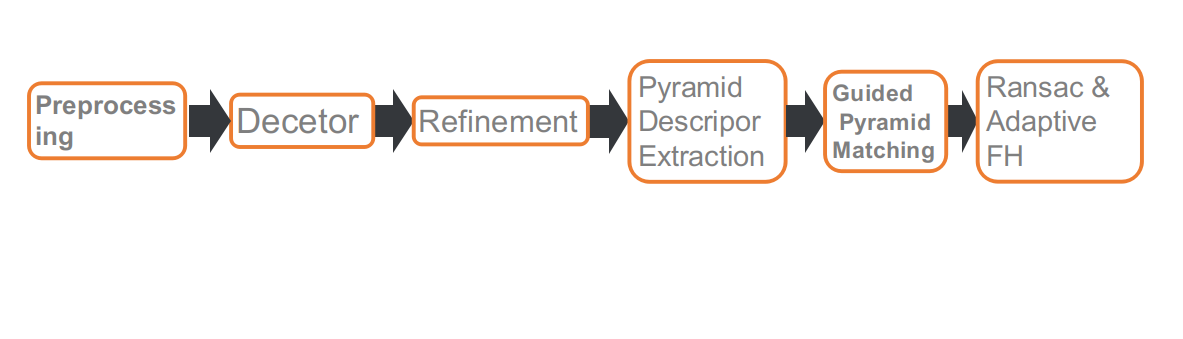
This is our competition pipeline, which consists of six parts: preprocessing, feature point detection, refining feature point positions, multi-scale or multi-angle descriptor extraction, guided matching, and RANSAC based on adaptive FH.
Preprocessing


The IMC track has a limitation on the number of feature points, so the position of the feature points becomes important. Some dynamic objects, such as pedestrians, vehicles, and the sky, do not contribute to pose estimation or may even have a negative impact. Therefore, we used a segmentation network to mask these objects, so that when extracting feature points, the masked areas would be skipped.
After using the segmentation network for preprocessing, we discovered two issues.
- One issue is that the segmentation network's accuracy is not high enough, and it cannot effectively distinguish between the connection areas of buildings and the sky, which can damage the edges of buildings, making matching more difficult. Therefore, after masking dynamic objects, we applied an erosion process to the masked areas to preserve the edge details of buildings.
- Another issue is that the segmentation network's generalization ability for distinguishing between real people and statues is not very good. When masking pedestrians, it also masks statues. In some scenes, such as the Lincoln dataset, the feature points on statues are important for matching results. To address this, we trained a classification network to distinguish between statues and pedestrians, allowing us to remove pedestrians while preserving statues.
Through preprocessing, we achieved a 1.1% and 0.3% improvement in the Phototourism validation set for the Stereo and Multiview tasks, respectively.
Feature Point Extraction
Adapt Homographic
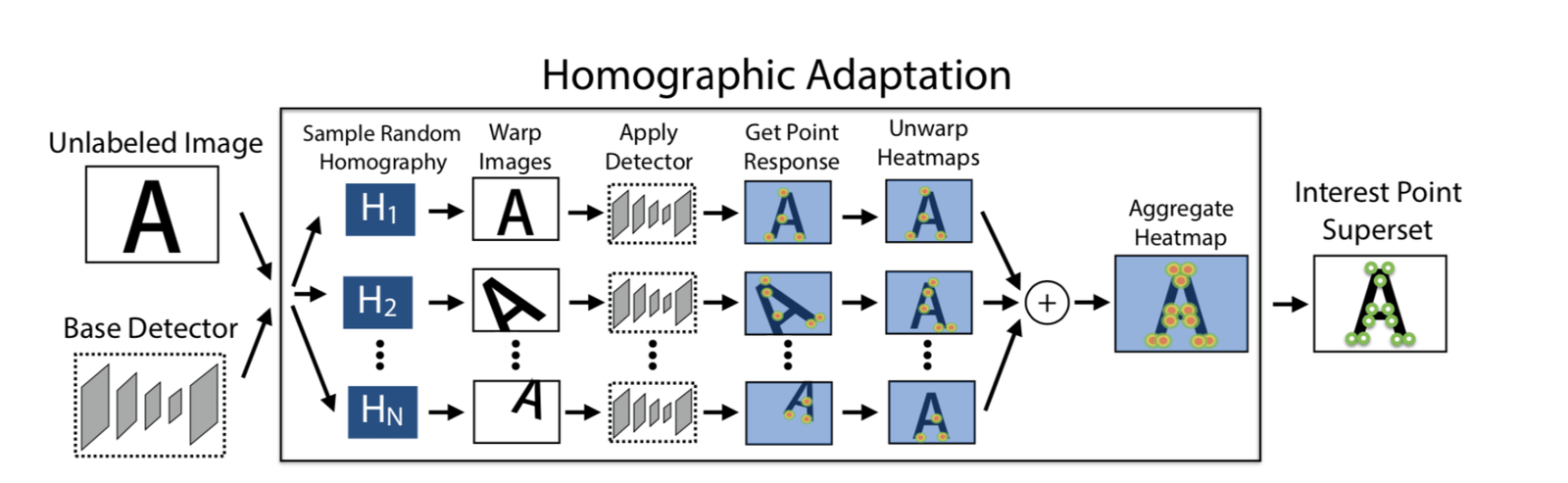
We applied 100 homography transformations to obtain 100 transformed images. Using the SuperPoint model, we extracted feature points from these images, generating n heatmaps of feature points. By stacking these n heatmaps, we obtained the final heatmap, from which we selected feature points as needed. The advantage of this approach is that it allows for the extraction of more feature points, and the positions of the feature points are more reasonable.
By using Adapt Homographic, we achieved a 1.7% and 1.3% improvement in the Phototourism validation set for the Stereo and Multiview tasks, respectively.
Refinement
The feature points extracted by SuperPoint are integers. We used soft argmax refinement with a radius of 2 to achieve sub-pixel accuracy, making the feature point positions more precise. Using the refinement method, we achieved a 0.8% and 0.35% improvement in the Phototourism validation set for the Stereo and Multiview tasks, respectively.
NMS

By observing the feature points extracted by the DISK method, we noticed that feature points tend to cluster densely, which results in some areas lacking feature points.
To alleviate this issue, we used a larger NMS radius, expanding the NMS radius from 3 to 10. As shown in the image, the clustering of feature points was improved. In the PragueParks validation set for the Stereo task, we achieved a 0.57% improvement.
Pyramid Descriptor && Guided Pyramid Matching
Analyzing Corner Cases


After building the baseline, we randomly sampled some images from the test set to analyze corner cases. Through our observations, poor matching results were mainly due to two situations, or a combination of both:
- Large scale differences
- Large angle rotations
To address these corner cases, we adopted a pyramid descriptor extraction and guided matching strategy.

We extracted descriptors based on the same set of feature points at different scales and angles. That is, the feature points were extracted from one image, and the descriptors were extracted from different images based on the mapping of the feature points.
During matching, we set a threshold t. If the number of matches exceeds the threshold t, we use the original scale or angle for matching. If the number of matches is below the threshold t, we use multi-scale or multi-angle matching.
After applying these corrections, the matching results for the corner cases improved.


Using the above strategy, we achieved an average improvement of 0.4% in the Stereo and Multiview tasks across the three datasets' validation sets.
Retrain SuperGlue
Additionally, we retrained SuperGlue, focusing on two aspects. First, we reproduced the official SuperPoint+SuperGlue method. Second, we used the more effective feature extraction method DISK to train DISK+SuperGlue. DISK+SuperGlue outperformed the official SuperPoint+SuperGlue by about 4% on the YFCC validation set.
For the competition datasets, DISK+SuperGlue performed well on Phototourism but poorly on the other two datasets, possibly because DISK was trained on Megadepth and overfitted to building datasets. In contrast, SuperPoint was trained on COCO, which contains more diverse scenes, giving it stronger generalization ability.
Finally, in the 8k track (unlimited keypoints), we ensembled SuperPoint+SuperGlue and DISK+SuperGlue, achieving better results than using either method alone.
| Methods | Phototourism | PragueParks | GoogleUrban | |||
|---|---|---|---|---|---|---|
| Stereo | Multiview | Stereo | Multiview | Stereo | Multiview | |
| SP-SG(4K) | 0.60357 | 0.78290 | 0.79766 | 0.50499 | 0.41212 | 0.32472 |
| DISK-SG(8K) | 0.61955 ↑ | 0.77531 | 0.72002 | 0.48548 | 0.38764 | 0.26281 |
| SP-DISK-SG | 0.63975 ↑ | 0.78564 ↑ | 0.80700 ↑ | 0.49878 | 0.43952 ↑ | 0.33734 ↑ |
RANSAC && Adapt FH
First, we tried various RANSAC methods, such as OpenCV's built-in RANSAC, DEGENSAC, and MAGSAC++. Through experiments, we found that DEGENSAC performed the best.
Additionally, when using the F matrix for solving in DEGENSAC, a planar degeneration problem can occur, as shown below.

To address the planar degeneration problem, inspired by ORB-SLAM, we designed an adaptive FH strategy. The specific algorithm is as follows:

Application: AR Navigation
Megvii places great importance on combining cutting-edge algorithms with real-world business applications. The Image Matching technology introduced in this article has already been applied in several projects, such as the S800V SLAM robot and AR navigation.
For example, in Megvii's "indoor visual positioning and navigation" project, relying on large-scale SfM sparse point cloud reconstruction technology and Image Matching, the Megvii 3D team achieved accurate positioning and AR navigation in complex indoor scenes using only a smartphone camera. Compared to traditional indoor positioning solutions like GPS and Bluetooth, "indoor visual positioning and navigation" offers centimeter-level mapping accuracy, sub-meter-level positioning accuracy, and requires no additional indoor scene setup, meeting customers' needs for "high precision and easy deployment/maintenance" in indoor positioning. The project has already won several large-scale indoor positioning and navigation contracts.
To provide a more intuitive experience of this technology, the indoor visual positioning and navigation app "MegGo" has been launched internally at Megvii, supporting indoor positioning and navigation across various work areas. Even in unfamiliar work areas, users can rely on this electronic "guide" to quickly and accurately navigate to destinations like meeting rooms. Visitors to Megvii can also download MegGo on their phones to experience indoor positioning and navigation within the work areas (the images below show visual positioning and AR navigation using MegGo).
[gif-player id="3304"]
Visual Positioning
[gif-player id="3305"]
AR Navigation
Future Outlook
- Reinforcement learning can be added during training to retrain the entire pipeline.
- Enhance the generalization ability of DISK by training on more datasets.
- Use Refinements networks to refine the positions of feature points.
References
1. D. DeTone, T. Malisiewicz, and A. Rabinovich, “SuperPoint: Self-supervised interest point detection and description,”CoRR, vol. abs/1712.07629, 2017.
2. M. Tyszkiewicz, P. Fua, and E. Trulls, “DISK: Learning local features with policy gradient,” Advances in Neural Information Processing Systems, vol. 33, 2020.
3. K. He, G. Gkioxari, P. Dollár, and R. B. Girshick,“Mask R-CNN,” CoRR, vol. abs/1703.06870, 2017.
4. H. Zhao, J. Shi, X. Qi, X. Wang, and J. Jia, “Pyramid scene parsing network,” in CVPR, 2017.
5. P.-E. Sarlin, D. DeTone, T. Malisiewicz, and A. Rabinovich, “SuperGlue: Learning feature matching with graph neural networks,” in CVPR, 2020.
6. D. Mishkin, J. Matas, and M. Perdoch, “Mods: Fast and robust method for two-view matching,” Computer Vision and Image Understanding, 2015.
7. C. Campos, R. Elvira, J. J. Gomez, J. M. M. Montiel, and J. D.Tardós, “ORB-SLAM3: An accurate open-source library for visual, visual-inertial and multi-map SLAM,” arXiv preprint arXiv:2007.11898, 2020.